KMeans++算法理论和实现
- https://github.com/Sean16SYSU/MachineLearningImplement
简述
在Kmeans当中,有两个限制
- 定义在凸欧式空间上,使得在非凸空间上的聚类效果一般,在非欧式空间上无法计算均值点。
- 病态初始化问题,由于初始化完全随机,会使得生成的点收到限制,最后聚类的结果不好
第一类问题的主流解决方案就是,转换距离度量的方式,这样能使得做到一定的扩展。但任然没有办法解决非欧式空间的问题。
KMeans++这篇论文主要关注于第二个问题。
- KMeans的算法和实现就不再赘述了。可以看 K-Means算法理论及Python实现
这里主要描述KMeans++的算法思路(聚焦于初始化)
- 先随机选一个点,作为初始的中心
之后,在其他没有选的点中,找到离已经选好的点最远的点(即,离中心点集中点的最小距离的值,在所有的没有被选中为中心点的点中是距离最大的点)
X i = a r g m a x i = 0 n ( min j = 1 m ∣ ∣ x i − c j ∣ ∣ 2 ) X_i = argmax_{i=0}^n( \min_{j=1}^m{||x_i - c_j||^2}) Xi=argmaxi=0n(j=1minm∣∣xi−cj∣∣2)- 其中n为点数,m为被选中心数
- 选出来的点放入中心集合中,一直到最后选完k个初始化的中心
- 之后,接着完成KMeans操作即可
很明显这样的点在一开始的时候就足够的分散,就不会出现病态初始化的问题了,虽然这样的计算量会很大。
Python实现
import numpy as npdef k_means_pp(X, k=3):def centroid_pick(X, k):node = np.random.randint(0, len(X))centroids = [node]while len(centroids) < k:centroids.append(np.argmax([np.min([np.linalg.norm(xi - cj) if i not in centroids else -np.inf for cj in centroids ]) for i, xi in enumerate(X)]))return np.array(centroids)centroids = X[centroid_pick(X, k)]y = np.arange(len(X))while True:y_new = np.arange(len(X))for i, xi in enumerate(X):y_new[i] = np.argmin([np.linalg.norm(xi - cj) for cj in centroids])if sum(y != y_new) == 0:breakfor j in range(k):centroids[j] = np.mean(X[np.where(y_new == j)], axis=0)y = y_new.copy()return y
用iris检查
from sklearn import datasets
iris = datasets.load_iris()
test_y = k_means_pp(iris.data)评估方式
def evaluate(y, t):
a, b, c, d = [0 for i in range(4)]for i in range(len(y)):for j in range(i+1, len(y)):if y[i] == y[j] and t[i] == t[j]:a += 1elif y[i] == y[j] and t[i] != t[j]:b += 1elif y[i] != y[j] and t[i] == t[j]:c += 1elif y[i] != y[j] and t[i] != t[j]:d += 1return a, b, c, d
def external_index(a, b, c, d, m):
JC = a / (a + b + c)FMI = np.sqrt(a**2 / ((a + b) * (a + c)))RI = 2 * ( a + d ) / ( m * (m + 1) )return JC, FMI, RI
def evaluate_it(y, t):
a, b, c, d = evaluate(y, t)return external_index(a, b, c, d, len(y))
得到的结果是
| External index | Value |
|---|---|
| JC | 0.6822787660436839 |
| FMI | 0.8112427991975698 |
| RI | 0.8621633554083885 |
- 实验效果
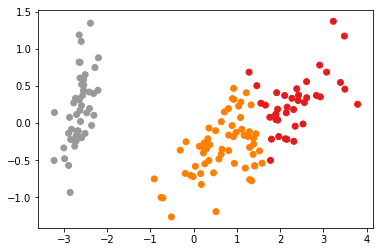
- 真实效果
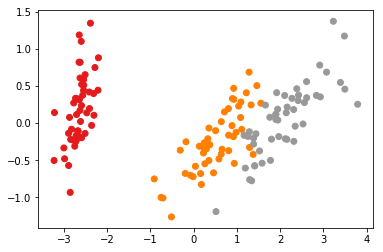

























")
实现")

算法")
之python实现")




还没有评论,来说两句吧...