《TextSnake:A Flexible Representation for Detecting Text of Arbitrary Shapes》论文笔记
代码地址:TextSnake
1. 概述
导读:为了解决任意形状文本的检测难题,文章提出了基于全卷积网络(Fully Convolutional Network,FCN)形式的文本检测器TextSnake,它是基于分割的文本检测方法。在该模型中将文本实例通过一串有序且重叠的圆盘组成,每个圆盘都有决定其属性的半径(文本宽度)与方向(文本方向),从而可以自由检测出任意形状的文本区域。
下面是分别使用传统水平框、带旋转角度的矩形框、任意四边形与文章提出方法进行文本区域检测得到的结果对比:
2. 方法设计
2.1 检测结果的表达
文中的检测算法得到的检测结果表达见图2所示,是由一系列的带角度的圆盘串联组成的,需要注意的是每个圆盘并不是与每个字符相对应的。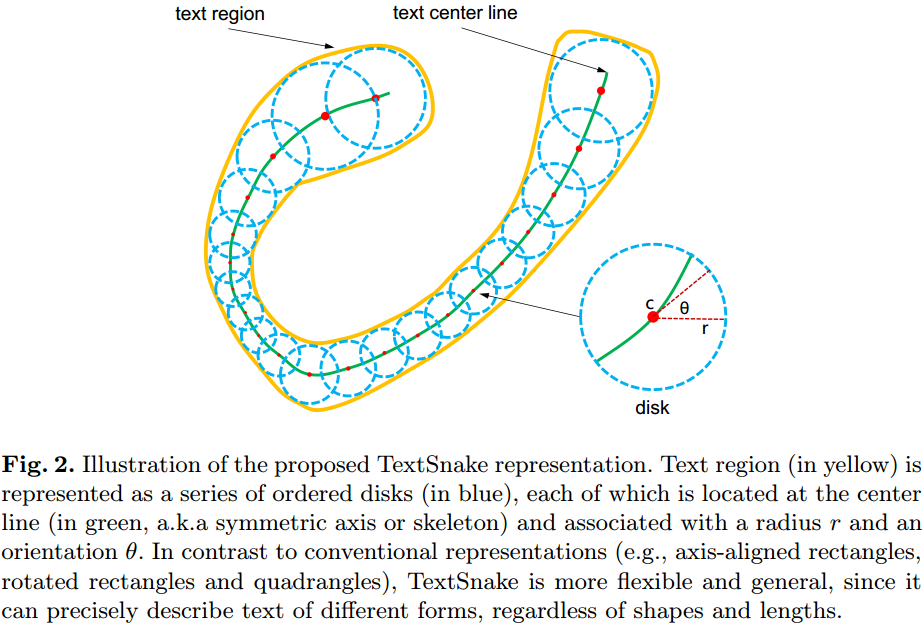
上面的一串圆盘可以使用一个集合进行表示, S ( t ) = { D 0 , D 1 , … , D n } S(t)=\{D_0,D_1,\dots ,D_n\} S(t)={ D0,D1,…,Dn},而每个圆盘有三个属性 D = ( c , r , θ ) D=(c,r,\theta) D=(c,r,θ),分别代表圆的中心、半径以及该圆的方向。该方向是过中心点c的正切方向。
2.2 方法的流程
文章的方法是基于FCN的,因而首先会预测生成文本区域(Text Region,TR,用于确定文本区域)与文本中心线(Text Center Line,TCL,用于区分开文本行),以及一些集合属性:半径 r r r、 c o s θ cos\theta cosθ、 s i n θ sin\theta sinθ。TCL与TR分割结果相与得到相与之后的掩膜Masked TCL。之后使用striding算法提取中心点的集合与重建的文本区域。其流程见图3
2.3 网络结构
文中采用的是VGG16作为主干网络,分成5个stage,其结构见图4所示。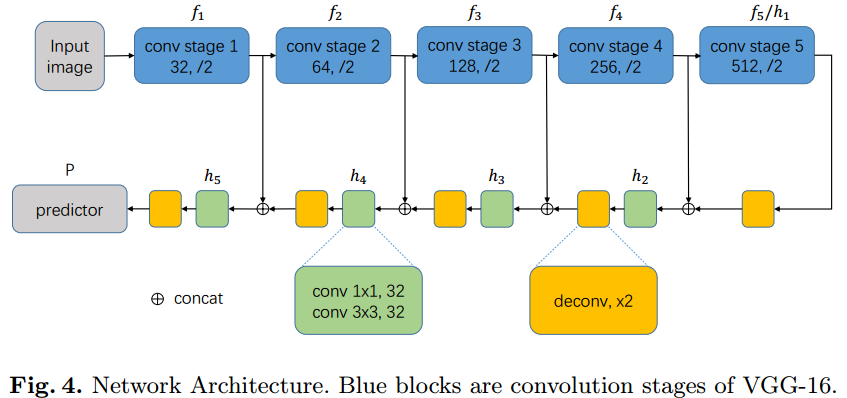
重建分割结果的过程中使用上采样与concat上一个stage的特征图的形式完成特征融合,其过程如下所示: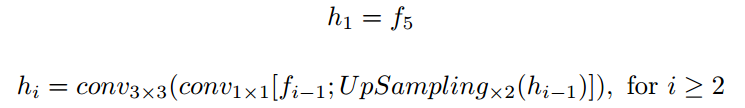
最后一个stage的处理过程如下:
其生成的结果 P ∈ R h ∗ w ∗ 7 P\in R^{h*w*7} P∈Rh∗w∗7,其中4个channel代表的是TR与TCL的逻辑分割,另外的3个channel代表的是 r , c o s θ , s i n θ r, cos\theta, sin\theta r,cosθ,sinθ。
2.4 网络Inference
网络在前向传播过程中会生成TCL与TR分割结果,之后使用阈值 T t c l T_{tcl} Ttcl与 T t r T_{tr} Ttr分别对两个分割的结果进行二值化操作。再将两者的二值化之后的结果取交集得到文本区域的分割掩膜,这样的好处是文本行之前可以极大减少粘连。
最后使用striding算法生成最后的文本区域,其算法运行流程如图5所示: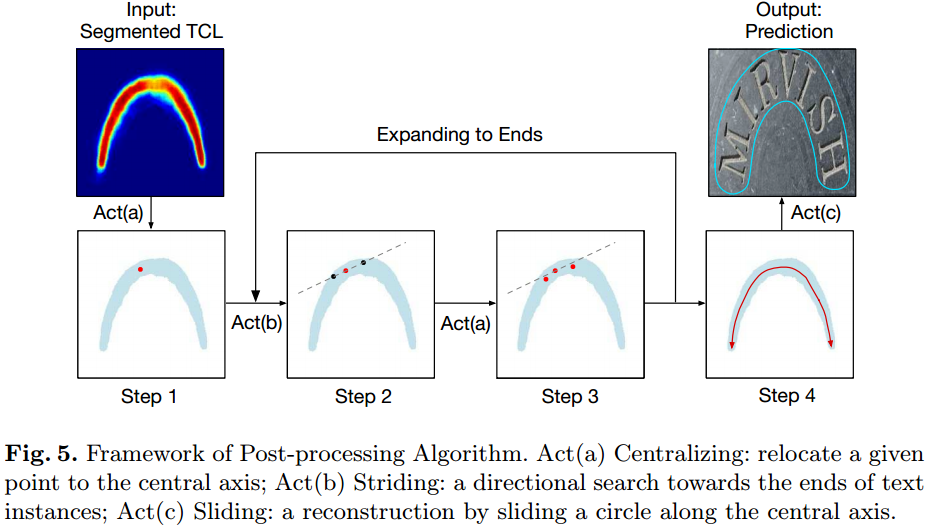
其中更有两个比较简单的准则可以用以排除一些无效的的TCL区域:
- 1)TCL区域的像素个数应该至少是其半径均值的0.2倍;
- 2)重建之后的文本区域应该有至少一半的像素在TR中;
文本检测的后处理可以分为三个步骤Act(a), Act(b),Act©,主要过程可以概括为:在分割结果上随机选择一个起始点,并将其中心化得到算法迭代的起始点,之从起始点开始往两头进行搜索,从而搜索得到文本区域。具体的操作步骤见图6所示: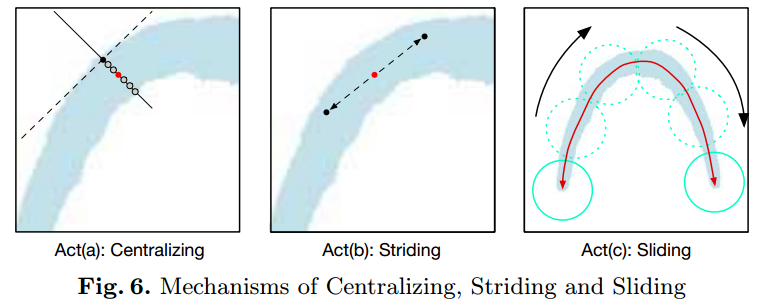
- 1)Act(a) Centralizing,随机选取分割结果外围的一个点,做该点的切线与法线,法线就会穿过文本区域,因而按着法线的方向进行搜索得到中心点;
- 2)Act(b) Striding,在进行文本区域搜索的过程中需要指定每次行进的步长,文中对于两个方向的搜索步长的定义为 ( 1 2 r ∗ c o s θ , 1 2 r ∗ s i n θ ) (\frac{1}{2}r*cos\theta , \frac{1}{2}r*sin\theta) (21r∗cosθ,21r∗sinθ)与 ( − 1 2 r ∗ c o s θ , − 1 2 r ∗ s i n θ ) (-\frac{1}{2}r*cos\theta , -\frac{1}{2}r*sin\theta) (−21r∗cosθ,−21r∗sinθ),如果搜索的点下一步超出了TCL区域,就减少搜索的步长,或者到达了区域的终点;
- 3)Act© Sliding将这些寻找到的点使用其对应的半径画圆,这些圆组成的区域就是对应的文本区域了;
2.5 标签生成
对于任意形状的文本区域其可以看做是一个多边形,则对于该多边形文本区域可以使用下面的流程生成文本区域的标注,其流程见图7所示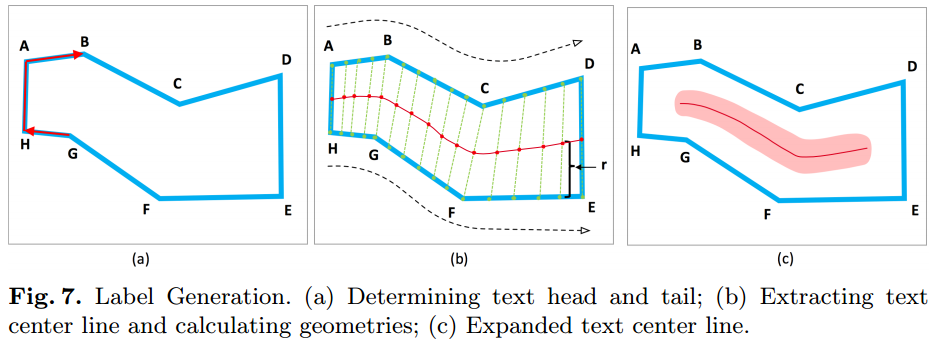
在图中将文本区域使用顺时针方向串联起来,则可以寻找到文本的左边界与右边界,文中近似将其假设为是平行的(估计是为了方面说明),如图a所示。之后在左右边界线条的中间间隔一定的距离寻找文本区域的中心线,图b图所示。之后对左右边界收缩 1 2 r e n d \frac{1}{2}r_{end} 21rend的距离进去,其它部分扩展 1 5 r \frac{1}{5}r 51r的范围,如图c所示(线条分割起来太难,还是扩展了一些)
对于之前文章中提到的参数 r , θ r,\theta r,θ, r r r是中心线与边界的距离, θ \theta θ是线上的倾斜角度(注意,这的标注是针对TCL区域,并不只针对中心线,否则如何训练呢)。对于其它的地方设置为0就可以了。
2.6 网络的损失函数
文章中将损失函数描述为TR与TCL组成的分割损失函数,半径与角度损失函数相加的形式,其定义如下: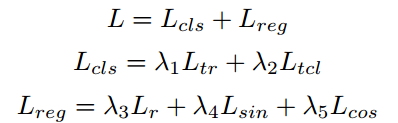
对于角度与半径的损失函数是使用SmoothedL1的形式: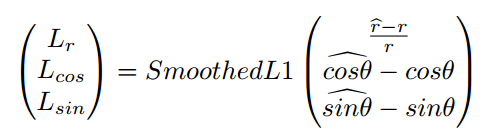
3. 实验结果
ICDAR2015数据集: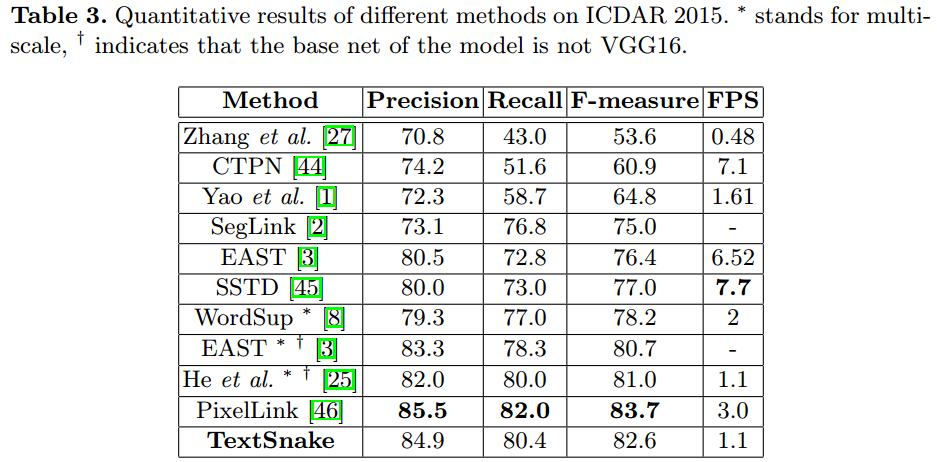


























图的概述")

之图像描述-根据网络模型结构图训练网络")





还没有评论,来说两句吧...