《Region Proposal by Guided Anchoring》论文笔记
代码地址:mmdetection
1. 概述
anchor机制算是现在大部分检测算法的基石,如今一些基于非anchor机制的检测算法也在不断涌现,其使用的是另外的一种方式寻找目标可能存在的位置。在anchor机制中使用一些预先设定好的固定的ratio和scale在空间上进行采样。这篇文章在这个固定的anchor上面进行改进,使用语义特征去指导anchor的生成。该改进能用于预测目标的位置以及不同位置处的ratio与scale。除此之外还是用feature adaption module减轻特征的不一致性(由于scale与ratio不固定带来的),同时研究了高质量的proposal去提升检测的性能。这篇文章的anchor机制可以无缝衔接到现有的检测器中去,对于FPN使用这篇文章提出的anchor机制在COCO数据集上召回率提升了9.1%,而anchor的数量减少了90%。同样的在Fast RCNN、Faster RCNN与RetinaNet上mAP分别提升了2.2%、2.7%和1.2%。
在诸如Faster RCNN的网络中使用固定的anchor预设,这一类的方法也在实际使用中展现了其有效性,但是通过固定预设anchor的方式得到的结果并不能保证结果是最优的,而且还导致了两个困难:
- 1)巧妙的anchor设计能够适配不同的检测目标,但是不好的设计却会影响检测器的速度与准确度;
- 2)为了获得足够的召回率,一般来讲会使用很多的anchor,但是其中有很多是负样本,与检测的目标毫不相关。这么多的anchor都是消耗大量的计算量,并且对网络的回归产生影响(正负样本差异太大);
由于目标并不是在图像中均匀分布的,且目标的scale与图像的内容、场景的位置与几何信息息息相关。基于此这篇文章提出对应的稀疏anchor,这个过程分为两步:1)确定子区域中是否包含目标;2)判断目标在不同位置处的形状;
按照前面的思路会在特征图上生成不同scale与ratio的anchor,而不是使用固定的值,这就使得网络能够适应不同anchor带来的子特征图,对此文章也提出了对应的适配模块。
文章的主要贡献:
- 1)提出了使用非同一与任意形状的anchor机制,替换原有的稠密且固定的方式;
- 2)用两个条件分布去构建联合anchor分布(location&shape),使用两个模块分别对其建模;
- 3)研究了对应anchor下特征对齐的重要性,并提出了一个自适应模块去减小非一致性;
- 4)试验了高质量的proposal对于两阶段检测器的影响,并针对已经训练好的模型提出改进的机制;
2. 网络设计
2.1 网络结构
对于检测框的表达一般为 ( x , y , w , h ) (x,y,w,h) (x,y,w,h),分别表示检测框的中心以及宽高,那么对于一幅图像 I I I,检测框的条件分布可以描述为:
p ( x , y , w , h ∣ I ) = p ( x , y ∣ I ) p ( w , h ∣ x , y , I ) p(x,y,w,h|I)=p(x,y|I)p(w,h|x,y,I) p(x,y,w,h∣I)=p(x,y∣I)p(w,h∣x,y,I)
也就是说检测框在图像中的位置任意,框的scale与ratio也与位置相关联。基于这样的关系得出下图1中所示的网络结构: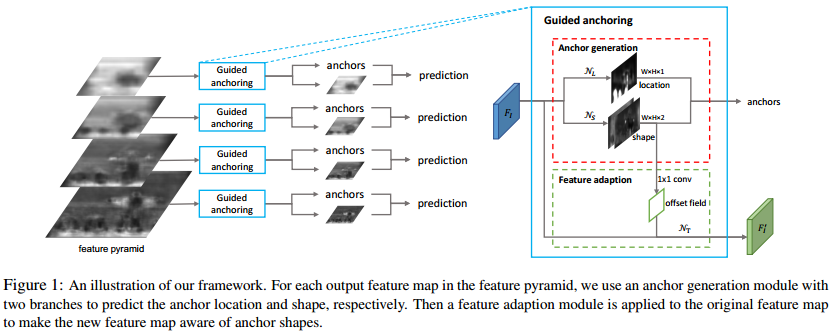
图1的左边是典型的FPN网络结构,右边的图就是这篇文章的核心Guided Anchoring模块了。这个模块可以细分为两个子模块部分:anchor generation与feature adaption。anchor generation通过两个分支生成目标的定位置信度(是否包含目标)与形状(scale与ratio),feature adaption主要用于特征校准。这个模块使用阈值在定位置信度上寻找可能的目标区域,并与对应的anchor组合生成anchor。
2.2 Anchor Location Prediction
这部分产生的结果就是相当于是一个heatmap,用以标明是否存在目标区域。该输出结果中的一个点的概率表示为 p ( i , j ∣ F 1 ) p(i,j|F_1) p(i,j∣F1),表示的是在原图 ( ( i + 1 2 ) s , ( j + 1 2 ) s ) ((i+\frac{1}{2})s,(j+\frac{1}{2})s) ((i+21)s,(j+21)s)位置处包含目标的概率(s为网络stride)。
这部分是在输入卷积 F 1 F_1 F1的基础上使用一个 1 ∗ 1 1*1 1∗1的卷积与sigmoid函数构成的子网络 N L N_L NL实现的(这是在效率与准确率上折中的结果)。在确定是否包含目标的时候使用了阈值 E l \mathcal{E}_l El,其带来的影响实验结果为: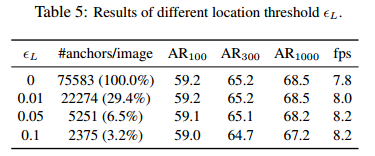
2.3 Anchor Shape Prediction
这部分是通过一个2通道的 1 ∗ 1 1*1 1∗1卷积子网络 N s N_s Ns实现的,这两个通道分别预测对应anchor的宽和高,则经过这两个anchor预测之后对应的anchor宽高计算为:
w = σ ∗ s ∗ e d w , h = σ ∗ s ∗ e d h w=\sigma*s*e^{dw},h=\sigma*s*e^{dh} w=σ∗s∗edw,h=σ∗s∗edh
其中, σ = 8 \sigma=8 σ=8(经验值)。这里不同于一个点上产生许多anchor,这里在一个点上只产生一个anchor,但是这个anchor是比较合适的,取得的效果比产生默认anchor的效果好。
2.4 Anchor-Guided Feature Adaption
在原有的固定anchor生成的检测算法中,网络已经习惯了固定anchor的表达,但是这里由于引入了变化的anchor这样特征就不再对齐了。对此提出了anchor-guided feature adaptation,其数学描述为:
f i ′ = N T ( f i , w i , h i ) f_i^{'}=N_T(f_i,w_i,h_i) fi′=NT(fi,wi,hi)
其中, f i f_i fi是第 i i i个特征的位置, ( w i , h i ) (w_i,h_i) (wi,hi)是对应的anchor形状。实际上这里使用anchor形状预测的特征生成一个offset特征并将其接入到 3 ∗ 3 3*3 3∗3的膨胀卷积中,最后获得特征图 f i ′ f_i^{'} fi′。
2.5 网络的损失函数
由于文章在原有的检测上面添加了两个预测分支,那么对应的应该也添加两个对应的损失函数用于回归,因而这篇文章的损失函数可以被定义为:
L = λ 1 L l o c + λ 2 L s h a p e + L c l s + L r e g L=\lambda_1L_{loc}+\lambda_2L_{shape}+L_{cls}+L_{reg} L=λ1Lloc+λ2Lshape+Lcls+Lreg
2.5.1 Anchor location target
这里对于anchor定位预测有点类似于分割label的设计,这里将可行的区域标注为1,其他情况就标注为0。对此呢,文章将检测框及周围的区域划分为3个部分:
- 1)CR(center region),是原图中范围在 R ( x g ′ , y g ′ , σ 1 w ′ , σ 1 h ′ ) R(x_g^{'},y_g^{'},\sigma_1w^{'},\sigma_1h^{'}) R(xg′,yg′,σ1w′,σ1h′)的区域;
- 2)IR(ignore region),是原图中范围在 R ( x g ′ , y g ′ , σ 2 w ′ , σ 2 h ′ ) / C R R(x_g^{'},y_g^{'},\sigma_2w^{'},\sigma_2h^{'})/CR R(xg′,yg′,σ2w′,σ2h′)/CR的区域;
- 3)OR(other region),是原图中范围不在CR与IR的区域;
最好的解释的话就是图2所示:
2.5.2 Anchor shape targets
这一部分需要两步完成GT与anchor之间的匹配:1)将anchor与一个GT进行匹配;2)预测anchor的宽和高看是否能与对应的GT最佳匹配;文章中生成的anchor用 a w h = { ( x 0 , y 0 , w , h ) } a_{wh}=\{(x_0,y_0,w,h)\} awh={ (x0,y0,w,h)}表示,GT用 ( x g , y g , w g , h g ) (x_g,y_g,w_g,h_g) (xg,yg,wg,hg)表示,对应提出的IoU计算表达为:
v I o U ( a w h , g t ) = max w > 0 , h > 0 I o U n o r m a l ( a w h , g t ) vIoU(a_{wh},gt)=\max_{w>0,h>0}IoU_{normal}(a_{wh},gt) vIoU(awh,gt)=w>0,h>0maxIoUnormal(awh,gt)
要是所有的结果都去参与这样的计算,这回很复杂,因而文章对此提出了采样近似的概念,使用9个采样去计算最匹配的anchor参数。找到最匹配的anchor之后其损失函数定义为:
L s h a p e = L 1 ( 1 − m i n ( w w g , w g w ) ) + L 1 ( 1 − m i n ( h h g , h g h ) ) L_{shape}=L_1(1-min(\frac{w}{w_g},\frac{w_g}{w}))+L_1(1-min(\frac{h}{h_g},\frac{h_g}{h})) Lshape=L1(1−min(wgw,wwg))+L1(1−min(hgh,hhg))
3. 实验结果
COCO数据集上的性能: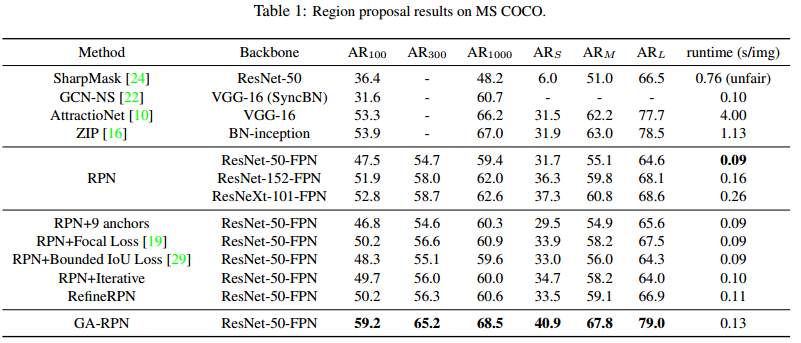
VOC数据集上的性能表现: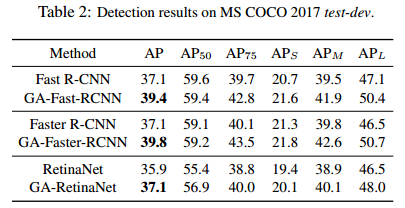
文中各模块对性能的影响: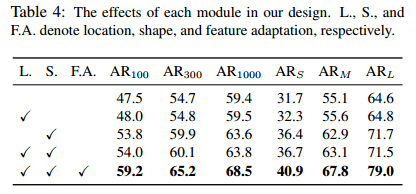



























")

实践篇 动手理解RabbitMQ五种模式 两小时搞定Rabbit应用 摸清路由器的的路由、广播、Topic 类型 了解Comfirm Return的过程")
:构建下一代基础设施 PDN")



还没有评论,来说两句吧...