Dubbo面试你问我答
文章目录
- 一、Dubbo是用来干什么的?
- 二、Dubbo能做什么?
- 三、谈一下你对Dubbo的理解【架构层次】
- 四、谈一下你对Dubbo的理解【框架设计层次】
- 五、了解Dubbo负载均衡策略吗?
一、Dubbo是用来干什么的?
首先:
随着互联网的发展,网站应用的规模不断扩大演变过程如下:
- 单一应用架构【此时数据访问ORM框架较重要】
- 垂直应用架构【加速前端页面开发的Web框架(MVC)较重要】
- 分布式服务架构【用于提高业务复用及整合的分布式服务框架(RPC)是关键】
- 流动计算架构【用于提高机器利用率的资源调度和治理中心(SOA)是关键】.。
抛去前两种架构,我们主要看一下分布式服务架构和SOA架构。分布式服务架构需要进行服务间的远程调用【因为不同的服务部署在不同的服务器上】,而SOA架构中服务治理则显得尤为重要。早期的SOA架构服务治理模块很重,而在分布式架构中,由于服务也会越来越多,所以需要服务治理,而我们又要摆脱之前重量级的服务治理,所以我们需要有一个可以进行服务治理,并且可以进行RPC调用这个基本功能的一个框架,而我们所说的DUBBO正好符合。
总的来讲:
- Dubbo是一个分布式服务框架,及SOA治理方案。功能主要包括:高性能NIO通讯及多协议集成,服务动态寻址与路由,软负载均衡与容错,依赖分析与降级等。
二、Dubbo能做什么?
**Dubbo服务治理图:**
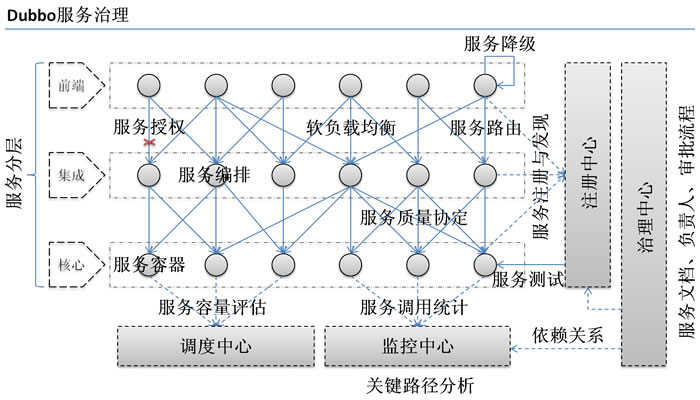
图片来自Dubbo官网。
- 大规模服务化之前,应用一般是通过诸如 RMI 或 Hessian 等工具,简单的暴露和引用远程服务,通过配置服务的URL地址进行调用,通过 F5 等硬件进行负载均衡。
- 当服务越来越多时,服务 URL 配置管理变得非常困难,F5 硬件负载均衡器的单点压力也越来越大。 此时需要一个服务注册中心,动态地注册和发现服务,使服务的位置透明。并通过在消费方获取服务提供方地址列表,实现软负载均衡和 Failover,降低对 F5 硬件负载均衡器的依赖,也能减少部分成本。
- 而随之进一步发展,服务间依赖关系变得错踪复杂,以至分不清哪个应用要在哪个应用之前启动,甚至架构师也无法完整的描述应用的架构关系。 这时,需要自动画出应用间的依赖关系图,以帮助架构师理清理关系。
- 接着,服务的调用量越来越大,服务的容量问题就暴露出来,这个服务需要多少机器支撑?什么时候该加机器? 为了解决这些问题,第一步,要将服务现在每天的调用量,响应时间,都统计出来,作为容量规划的参考指标。其次,要可以动态调整权重,在线上,将某台机器的权重一直加大,并在加大的过程中记录响应时间的变化,直到响应时间到达阈值,记录此时的访问量,再以此访问量乘以机器数反推总容量。
综上所述dubbo提供了负载均衡、服务调用链路生成、服务访问压力以及时长统计、资源调度和治理、服务降级等功能。
三、谈一下你对Dubbo的理解【架构层次】
- 首先看一下 官网提供的架构图:
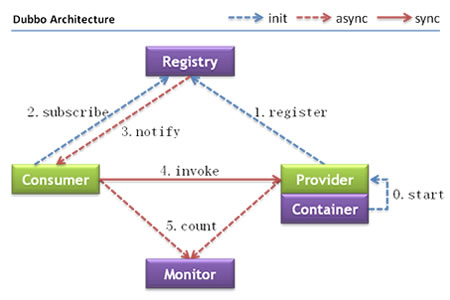
角色说明:
- Provider : 暴露服务的服务提供方
- Consumer : 调用远程服务的服务消费方
- Registry : 服务注册与发现的注册中心
- Monitor : 统计服务的调用次数和调用时间的监控中心
- Container : 服务运行容器
流程解析:
- 服务容器负责启动,加载,运行服务提供者。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
架构特点:
- 架构特点[连通性]:
- 注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小
- 监控中心负责统计各服务调用次数,调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示
- 服务提供者向注册中心注册其提供的服务,并汇报调用时间到监控中心,此时间不包含网络开销
- 服务消费者向注册中心获取服务提供者地址列表,并根据负载算法直接调用提供者,同时汇报调用时间到监控中心,此时间包含网络开销
- 注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外
- 注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者
- 注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表
- 注册中心和监控中心都是可选的,服务消费者可以直连服务提供者
- 架构特点[健壮性]:
- 监控中心宕掉不影响使用,只是丢失部分采样数据
- 数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
- 注册中心对等集群,任意一台宕掉后,将自动切换到另一台
- 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
- 服务提供者无状态,任意一台宕掉后,不影响使用
- 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
- 架构特点[伸缩性]:
- 注册中心为对等集群,可动态增加机器部署实例,所有客户端将自动发现新的注册中心
- 服务提供者无状态,可动态增加机器部署实例,注册中心将推送新的服务提供者信息给消费者
- 架构特点[升级性]:【这里略过】
四、谈一下你对Dubbo的理解【框架设计层次】
- 首先看一下dubbo-framework图解:
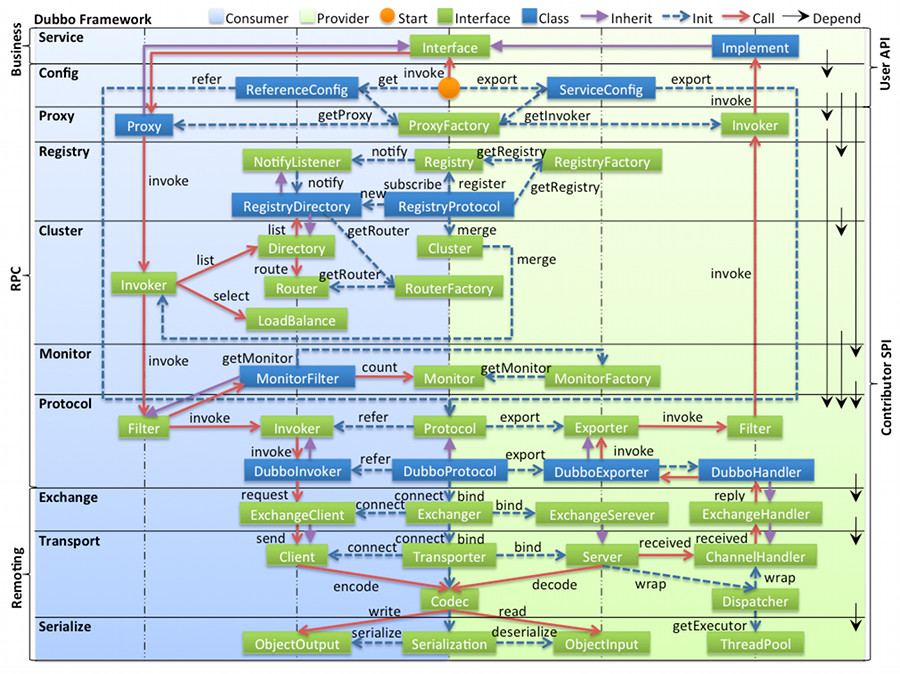
- 框架总结:
第一层:service层,接口层,给服务提供者和消费者来实现的
第二层:config层,配置层,主要是对dubbo进行各种配置的
第三层:proxy层,服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton
第四层:registry层,服务注册层,负责服务的注册与发现
第五层:cluster层,集群层,封装多个服务提供者的路由以及负载均衡,将多个实例组合成一个服务
第六层:monitor层,监控层,对rpc接口的调用次数和调用时间进行监控
第七层:protocol层,远程调用层,封装rpc调用
第八层:exchange层,信息交换层,封装请求响应模式,同步转异步
第九层:transport层,网络传输层,抽象mina和netty为统一接口
第十层:serialize层,数据序列化层,网络传输需要- service和config层属于API其他各层属于SPI。
- Protocol层属于RPC核心,只要有 Protocol + Invoker + Exporter 就可以完成非透明的 RPC 调用,然后在 Invoker 的主过程上 Filter 拦截点。
Cluster 是外围概念,所以 Cluster 的目的是将多个 Invoker 伪装成一个 Invoker。Proxy 层封装了所有接口的透明化代理,而在其它层都以 Invoker 为中心,只有到了暴露给用户使用时,才用 Proxy 将 Invoker 转成接口,或将接口实现转成 Invoker,也就是
而 Remoting 实现是 Dubbo 协议的实现,如果你选择 RMI 协议,整个 Remoting 都不会用上,Remoting 内部再划为 Transport 传输层和 Exchange 信息交换层,Transport 层只负责单向消息传输,是对 Mina, Netty, Grizzly 的抽象,它也可以扩展 UDP 传输,而 Exchange 层是在传输层之上封装了 Request-Response 语义。Registry 和 Monitor 实际上不算一层,而是一个独立的节点,只是为了全局概览,用层的方式画在一起。
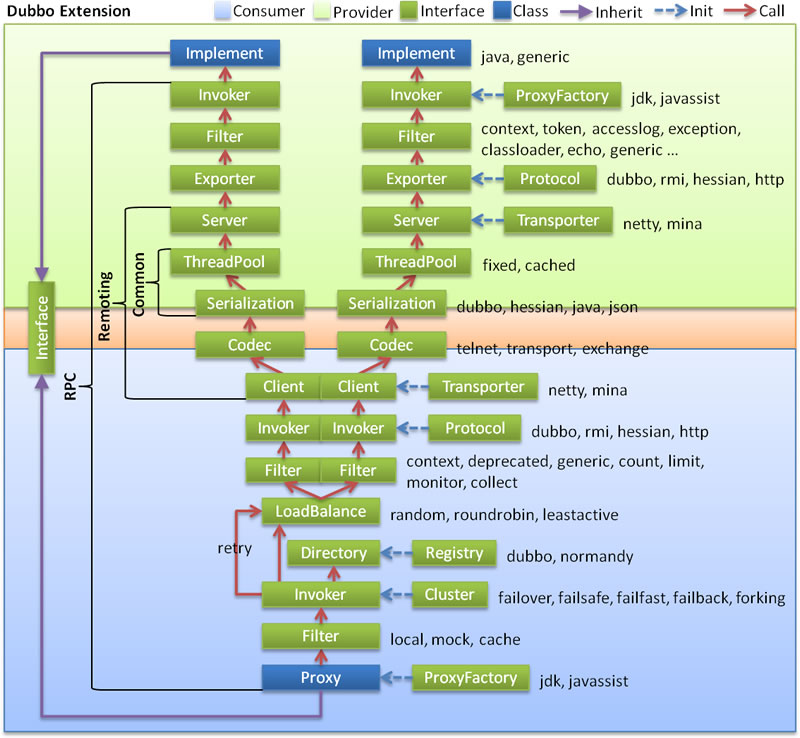
- 调用链dubbo-extension图解:
五、了解Dubbo负载均衡策略吗?
详情请见Dubbo负载均衡策略.
- 其他Dubbo文章相关:
- Dubbo实现基本思路
- Dubbo-加载初始化
- Dubbo-双检查锁
- Dubbo-SPI机制
- Dubbo-支持的通信协议
- Dubbo-基于Spring开发(自定义标签及解析)


































还没有评论,来说两句吧...