走进SparkStreaming
Spark Streaming类似于Apache Storm,但是sparkStreaming用于微批实时处理。官方文档介绍,Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用SparkRDD如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。另外Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合。
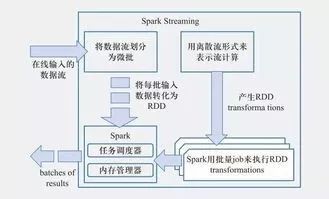
One.什么是微批实时处理?
微批实时处理并不是真正的实时,只不过是因为批处理的速度较快而达到了类似实时的效果,就像坐电梯一样,我们把一批数据装入电梯,然后一批批的去输送,当然,每一批的间隔是以秒级别的,
Two.为什么需要SparkStreaming
- Ease of Use(易用)
- Fault Tolerance(容错)
- Spark Integration(易整合到Spark体系)
Three.Strom与Spark的对比:
Strom:
- 实时计算模型:纯实时,来一条数据,处理一条数据.
- 实时计算延时度:毫秒级
- 吞吐量:低
- 事务机制:支持完善
- 容错性:Zookeeper,Acker,非常强
- 动态调整并行度:支持
Spark Streaming
a.实时计算模型:准实时(微批),对一个时间段内的数据收集起来,作为一个Rdd在处理.
b.实时计算延时度:秒级
c.吞吐量:高
d.事务机制:支持,不完善
e.容错性:Checkpoint,WAL,一般
d.动态调整并行度:不支持
Four.了解Dstream
SparkStreaming提供了一个叫做离散流或Dstream的高级抽象,它代表连续的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDDs序列。每个RDD含有一段时间间隔内的数据。
Five.strom与sparkstreaming的应用场景
Strom:
- strom需要纯实时的环境,不能忍受1秒以上的延迟环境,比如银行类的金融系统
- 如果在实时计算中要保证事务性的话,同样还是银行,数据要非常精准,
- 需要最大限度的利用集群资源,也可以考虑Strom.
Sparkstreaming:
- 不要求纯实时,不要求强大可靠的事务机制,不要求动态调整并行度,那么可以考虑使用Spark Streaming
- 考虑使用Spark Streaming最主要的一个因素,应该要针对整个项目进行宏观的考虑,如果一个项目除了实时计算之外,还包括了其他业务功能.就要考虑使用Sparkstreaming.





























")





还没有评论,来说两句吧...