mysql 查询速度为变慢
分析阶段
1、观察,至少跑1天,看看生产的慢sql 情况
2、开启慢查询日志设置阈值,比如超过5秒就是慢sql, 抓取出来
3、explain+慢sql分析
4、show profile
5、运维经理 or DBA,进行sql 数据库服务器的参数调优
总结:
1:慢查询的开启获取2:explain+慢sql分析3:show profile查询sql在mysql 服务器里面的执行细节和生命周期情况4:sql 数据库服务器的参数调优
小表驱动大表
for(int i=5:。。){for(int i = 1000){}}for(int i=10000:。。){for(int i = 5){}}

exist
select … from table where exist(subquery)
改语法可以理解:将主查询的数据放到子查询中做条件验证,根据验证结果(true/fasle)来决定主查询的结果是否保留
1:exists(subquery) 只返回true或者false,因此子查询中的select * 也可以是select 1 或者 select ‘X’ 官方说是忽略select 清单所以么有区别
告警排序使用索引orderBy排序优化
1、 order by 子句,尽量使用index 方式排序,避免使用FileSort 方式排序
a:键表 (age, birth)两个字段,复合索引case![watermark_type_ZmFuZ3poZW5naGVpdGk_shadow_10_text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2h1eXVucWlhbmcxMTE_size_16_color_FFFFFF_t_70 1][]![watermark_type_ZmFuZ3poZW5naGVpdGk_shadow_10_text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2h1eXVucWlhbmcxMTE_size_16_color_FFFFFF_t_70 2][]mysql 支持两种方式排序,filesort和index,index效率高,它指mysql扫描索引本身完成排序。fileSort 排序效率低下order by 满足两种情况,使用index方式A: roder by 使用索引最左前缀B: 使用where 子句 和order by 子句条件列满足索引最左前缀
2、尽可能在索引上完成排序,遵照索引键的最佳左前缀
3、如果不在索引列上,fielesort有两种算法:
4、优化策略
a:增大sort\_buffer\_size 参数设置b: max\_length\_for\_sort\_data 参数设置
why
![watermark_type_ZmFuZ3poZW5naGVpdGk_shadow_10_text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2h1eXVucWlhbmcxMTE_size_16_color_FFFFFF_t_70 3][]
小总结:
![watermark_type_ZmFuZ3poZW5naGVpdGk_shadow_10_text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2h1eXVucWlhbmcxMTE_size_16_color_FFFFFF_t_70 4][]
告警排序使用索引groupBy排序优化 和order by1基本相同
1、group by 实质是先排序后进行分组,遵照索引键的最佳左前缀
2、无法使用索引列,增大参数
3、where 高于having 能在where 中搞定的就不要写在where中
mysql 慢查询日志
是什么:
mysql 提供了一组日志文件用来记录sql 响应时间阈值的SQL,具体时间超过 long\_query\_time,则会被记录到查询日志中
默认时10秒,可以设置时间。
mysql 默认情况是么有开启一般不会开启,在不是特定的情况下不要打开
SHOW VARIABLES LIKE '%long_query_time%'
查看是否开启以及如何开启
SHOW VARIABLES LIKE '%slow_query_log%'slow_query_log ONslow_query_log_file DESKTOP-KDVRNUT-slow.log
开启:只是在当前库中开启,如果需要永久开启需要在配置文件中开启
set global slow_query_log=1修改my.cnfslow_query_log=1slow_query_log_file=var/lib/slow.loglong_query_time=3;log_output=FILE
开启了慢查询日志后,什么杨的sql 才会记录到慢查询日志中
1、 超过我们设置的阈值的sql
2、 设置阈值 set global long_query_time=3
3、出问题的sql 会在日志文件中打印出来
日志分析工具mysqldumpslow

用show_profile分析sql
说明:是mysql提供的可以用来分析当前会话中语句执行资源消耗情况,可以用于SQL调优
官网:
默认是处于关闭状态的,并保存最近15次的运行结果
分析步骤:
**1、看mysql 版本是否支持 **show VARIABLES like 'profiling'profiling ON开启:set profiling=on;**2、运行sql**** 3、 查看结果 show profiles;**
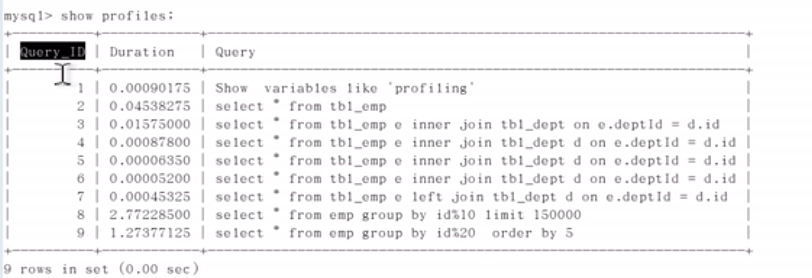
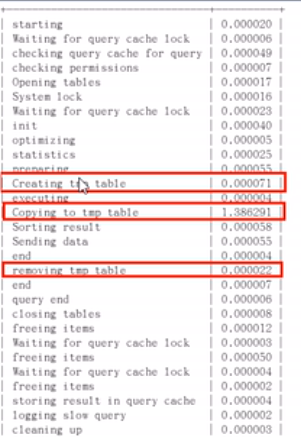
4、sql 语句分析show profile cpu.block io for query 8;
一下四种出现sql 一定有问题

查询优化、索引优化、库表结构优化齐头并进才能保证出一条高效的查询策略。
1、不要向数据库请求不需要的数据
2、确定mysql 是否扫描了额外的记录
1、衡量 mysql 开销的三个指标
响应时间扫描行数返回行数在explain 的type 列反应了访问类型:全表扫描、索引扫描、范围扫描、唯一索引查询、常用引用。速度由慢到快。在不确定的情况下加一个合理的索引 能够有效的减少我们扫描的行数,返回我们需要的数据。
2、mysql 使用三种方式应用where
![watermark_type_ZmFuZ3poZW5naGVpdGk_shadow_10_text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2h1eXVucWlhbmcxMTE_size_16_color_FFFFFF_t_70 9][]
3、如果需要扫描大量的数据来返回少量的数据我们的优化方法 为
- 使用索引覆盖扫描,把需要用的列到放到索引中,这个存储引擎无需回表获取对应行就可以返回结果了
- 改变库表结构(使用单独的汇总表)
- 重写这个复杂的从查询,让mysql 优化器能够以更优化的方式来致行这条sql
3、重构查询方式
1、一个复杂的查询还是多个简单的查询
2、切分查询
将一个大的查询拆分为小的查询,每个查询功能都一样,只完成一小部分数据![watermark_type_ZmFuZ3poZW5naGVpdGk_shadow_10_text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2h1eXVucWlhbmcxMTE_size_16_color_FFFFFF_t_70 10][]
3、分解关联查询
阿里巴巴开发手册不建议使用超过三个join连接。可以将一个复杂的关联查询查分成简单的单边查询,在应用程序中关联
优势:让缓存的效率更高单个查询减少锁的竞争IN()代替关联查询可以按ID的顺序致行,比随机的致行效率要高的多![watermark_type_ZmFuZ3poZW5naGVpdGk_shadow_10_text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2h1eXVucWlhbmcxMTE_size_16_color_FFFFFF_t_70 11][]
4、查询致行基础
1,mysql 发送一个请求后都做了哪些事
![watermark_type_ZmFuZ3poZW5naGVpdGk_shadow_10_text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2h1eXVucWlhbmcxMTE_size_16_color_FFFFFF_t_70 12][]
2、mysql 能够处理的优化类型
5、索引优化
1 索引的优点 :
提高少量数据的获取 / 减少扫描的行数/检索速度
2 索引的缺点 :
- 占用存储空间
- 多个索引耗费索引的挑选时间
- 降低写操作的性能,需要实时维护索引
- 并发情况下索引的维护高度复杂
3 什么时候不使用索引 :
- 数据的重复度高 , 即:选择率高
- 选择率高于 10%, 建议不考虑使用这个索引
- 表的数据量较少
4 使用索引的条件
- 一个经常查询的字段 大于,小于,或者 in(),模糊查询
- 主键和外键一般需要索引
- sql 执行查询的频率非常高
- 只利用索引来读取数据 select 列为索引列是不扫描全表的
5 索引失效情况
- like “%name” 或者 like “%name%” 这种查询会导致索引失效全表扫描。但是可以使用 like “name%”
- 如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)
- 如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
- not in ,not exist.
- 查询条件上不能有运算 select * from test where id-1=9;
- 使用操作符对索引的影响 !=
6、子查询优化
用子查询效率确实更低,因为这里每次子查询每次都需要建立临时表,它会把结果集都存到临时表,这样外部查询select count(*)又重新扫描一次临时表,导致用时更长,扫描效率更低
可以优化那些格式的子查询
带有DISTINCT、ORDERBY、LIMIT操作的简单SELECT查询中的子查询MySQL不支持对如下情况的子查询进行优化:带有UNION操作。带有GROUPBY、HAVING、聚集函数。使用ORDERBY中带有LIMIT。内表、外表的个数超过MySQL支持的最大表的连接数。
支持那些子查询优化技术
支持那类型的子查询进行优化
7、视图优化
使用试图存储过程优化
8、sql 优化
sql 优化
2、MySQL 的 LIMIT 优化技术
3、in子查询查询优化
SELECT a.* FROM tb_article as aWHERE a.cate_id in (SELECT b.cate_id FROM tb_article_cate b WHERE parent_id =10)
- mysql 不会按上面的先查询子查询和语句 会将相关联的外表压到子查询中
需要关联外表所以mysql 无法先执行这个子查询 mysql执行流程为
SELECT a.* FROM tb_article as a
where EXISTS(SELECT b.* FROM tb_article_cate b WHERE parent_id =10AND a.cate_id = b.cate_id
)
通过 EXPLAIN 分析SQL 语句:是对主表进行了全表扫描 在根据返回的 id逐个查询,如果主表数据量非常大查询效率是非常慢的。

用内连接优化子查询
inner join 在执行的时候回自动选择最小的表做基础表,效率高,不会进行全表扫描
EXPLAIN SELECT a.* FROM tb_article as aINNER JOIN tb_article_cate b USING(cate_id)WHERE b.parent_id =10
4、union的限制
如果将两个子查询中的结果合并取前20条 会将两个表中的所有数据放到临时表中在取前20条,查询效率是很慢的,但是我们去两个表中各自的前20条在合并临时表中只放人了40条数据在取前20条
可以优化可以优化什么格式的子查询什么格式的子查询
可以优化什么格式的子查询
可以优化什么可以优化什么格式的子查询格式的子查询




























还没有评论,来说两句吧...