python对文件的操作
1、文件操作类型有:r、w、a、r+、w+、a+、rb、wb、ab
r 文件的读取(只读)
f = open(文件路径, mode=”模式”, encoding=”编码格式”)
读的路径有两种:绝对路径和相对路径相对路径:也就是相对当前执行文件所在的路径,其中("../"就是返回上一层目录)绝对路径:就是相对系统的根目录所在的路径f = open("file/wuse", mode="r", encoding="utf-8")s = f.read()f.close() # 关闭句柄print(s)
w 对文件有写操作(# 写入之前会情掉原来的内容)
f = open("小护士模特", mode="w", encoding="utf-8")f.write("杜十娘")f.flush()f.close()
a 读写操作(# 在原来的基础上进行追加内容.)
原文件内容 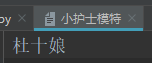
f = open("小护士模特", mode="a", encoding="utf-8")f.write("小龙女")f.flush()f.close()
执行程序后的内容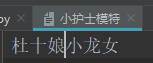
rb bytes 读写操作的是字节. 用在非文本上,如果要打印出字符串则还需要进行解码
f = open("小护士模特",mode="rb") # 读取的内容直接就是字节bs = f.read()print(bs.decode("utf-8")) # 需要解码f.close()
wb 需要进行编码操作否则会报错,如下
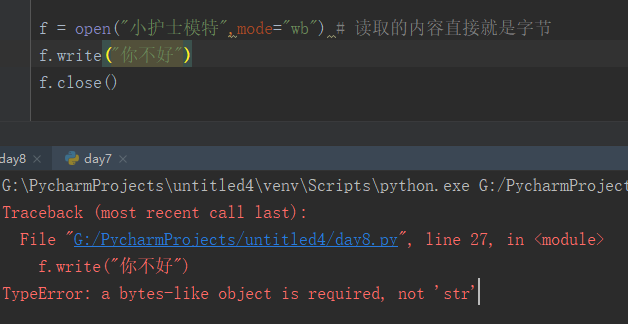
正确操作如下
f = open("小护士模特",mode="wb") # 读取的内容直接就是字节f.write("你不好".encode("utf-8"))f.close()
r+ 读写模式.
需要移动光标进行反复读写
r+模式, 默认情况下光标在文件的开头, 必须先读, 后写不管你前面读了几个. 后面去写都是在末尾f = open("老师点名", mode="r+", encoding="utf-8") # r+模式, 默认情况下光标在文件的开头, 必须先读, 后写f.write("周润发")s = f.read()f.flush()f.close()print(s)1.在没有任何操作之前进行写. 在开头写2. 如果读取了一些内容. 再写, 写入的是最后f = open("精品", mode="r+", encoding="utf-8")s = f.read(3)f.write("哈哈")print(ss)truncate()截断strip() 去掉空格. 还能去掉\n和\t
2、seek() 移动光标到xx位置
开头: seek(0), 末尾: seek(0,2)
移动到开头: f.seek(0) 开头移动到末尾: f.seek(0, 2) 末尾 第二个参数有三个值. 0: 再开头, 1: 在当前, 2: 末尾f = open("文件", mode="r+", encoding="utf-8")f.read(3)f.seek(3) # 移动到xx位置
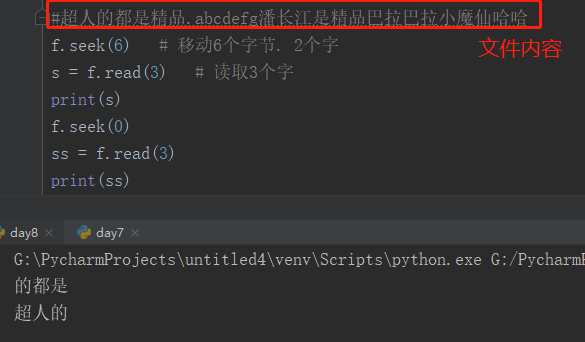
3、文件的修改
修改原理:创建新文件. 把修改后的内容写入新文件. 删除老文件. 重命名新文件调用的新模块: import osos.remove("")删除文件os.rename("源文件", "新文件名") 重命名文件
讲课试题:将文件名为“吃的”的文件中所含有的“肉”字都替换成“菜”
常见思路:
with open(“文件名”) as f:
不需要关闭文件句柄
import oswith open("吃的", mode="r", encoding="utf-8") as f1, \open("吃的_副本", mode="w", encoding="utf-8") as f2:s = f1.read()ss = s.replace("肉", "菜")f2.write(ss)os.remove("吃的") # 删除文件os.rename("吃的_副本", "吃的") # 重命名文件
使用迭代方式:
for line in f:line 一行数据import oswith open("吃的", mode="r", encoding="utf-8") as f1, \open("吃的_副本", mode="w", encoding="utf-8") as f2:for line in f1:s = line.replace("菜", "肉")f2.write(s)os.remove("吃的") # 删除文件os.rename("吃的_副本", "吃的") # 重命名文件
作业:
1、文件内容如下:

将文件全部读出来
f=open("a.txt", mode="r", encoding="utf-8")s=f.read()print(s)f.close()
或
with open("a.txt", mode="r", encoding="utf-8") as f:for i in f:print(i.strip())
在文件末尾添加一行内容为“信不信由你,反正我是信了”
f=open("a.txt", mode="a", encoding="utf-8")f.write("\n信不信由你,反正我是信了")f.flush()f.close()
将文件全部读出来,并在末尾新增一行内容为“信不信由你,反正我是信了”
f=open("a.txt", mode="r+", encoding="utf-8")f.read()f.write("\n信不信由你,反正我是信了")f.flush()f.close()
将文件清空并换成一下内容
f=open("a.txt", mode="w", encoding="utf-8")f.write("每天坚持一点,\n每天努力一点,\n每天多思考一点,\n慢慢你会发现,\n你的进步越来越大。")f.flush()f.close()
或
f=open("a.txt", mode="w+", encoding="utf-8")f.write("""每天坚持一点,每天努力一点,每天多思考一点,慢慢你会发现,你的进步越来越大。""")f.flush()f.close()
在上一题基础上再”慢慢你会发现,”一行前加上“时间久了,”一行内容
import oswith open("a.txt",mode="r",encoding="utf-8") as f1,\open("a_new.txt",mode="w",encoding="utf-8") as f2:s=f1.read()ss=s.replace("慢慢你会发现,","时间久了,\n慢慢你会发现,")f2.write(ss)os.remove("a.txt")os.rename("a_new.txt","a.txt")2、有以下文件内容序号 部门 人数 平均年龄 备注1 python 30 26 单身狗2 linux 26 30 没对象3 运营部 20 24 女生多
要求:将文件内容按以下模式[{‘序号’: ‘1’, ‘部门’: ‘python’, ‘人数’: ‘30’, ‘平均年龄’: ‘26’, ‘备注’: ‘单身狗’, ‘tianjia’: ‘q’}],将文本文件内容输出
f=open("a.txt",mode="r",encoding="utf-8")s=f.readline().split()print(s)list=[]for j in f:dic={}ss=j.split()for i in range(len(ss)):dic[s[i]]=ss[i]list.append(dic)print(list)


























图的概述")

之图像描述-根据网络模型结构图训练网络")





还没有评论,来说两句吧...