Spark RDD的实操教程(二)
教程目录
- 0x00 教程内容
- 0x01 RDD 的算子操作
- 算子介绍
- a. 两种算子类型
- b. 举个例子
- c. 总结
- 转化算子(transformations算子)
- 行动算子(actions算子)
- 0x02 RDD 算子实操
- 创建 RDD
- 转化算子
- 行动算子
- 0xFF 总结
0x00 教程内容
- RDD 的算子操作介绍
- RDD 算子实操
上一篇教程:Spark RDD的实操教程(一) 我们已经对RDD有了基本的认识,接下来我们继续学习各种各样的算子。
0x01 RDD 的算子操作
1. 算子介绍
RDD 支持两种算子操作,分别是转换(transformations)算子和行动(actions)算子。算子,你可以理解为就是所谓的函数,调用某个算子,调用某个函数,都是一个意思。
a. 两种算子类型
转换算子:对 RDD 进行转化所需要用到的算子,将已存在的数据集 RDD 转换成新的数据集 RDD。如前面的教程说使用到的 map 算子:
val wordRDD = textFileRDD.flatMap(line => line.split(“ “))
其实就是对一个 textFileRDD 进行了转化,转化成了 wordRDD。而 flatMap 就是属于一个转化算子,这样的算子有很多,后面我们会介绍到。
- 动作算子 :在数据集 RDD 上进行计算后,返回一个结果值给驱动程序的算子,行动算子可以触发代码的执行,我们一段 Spark 代码里面至少需要有一个行动操作。
b. 举个例子
val textFileRDD = sc.textFile("/home/hadoop-sny/datas/word.txt")val wordRDD = textFileRDD.flatMap(line => line.split(" "))val pairWordRDD = wordRDD.map(word => (word, 1))val wordCountRDD = pairWordRDD.reduceByKey((a, b) => a + b)wordCountRDD.foreach(println)
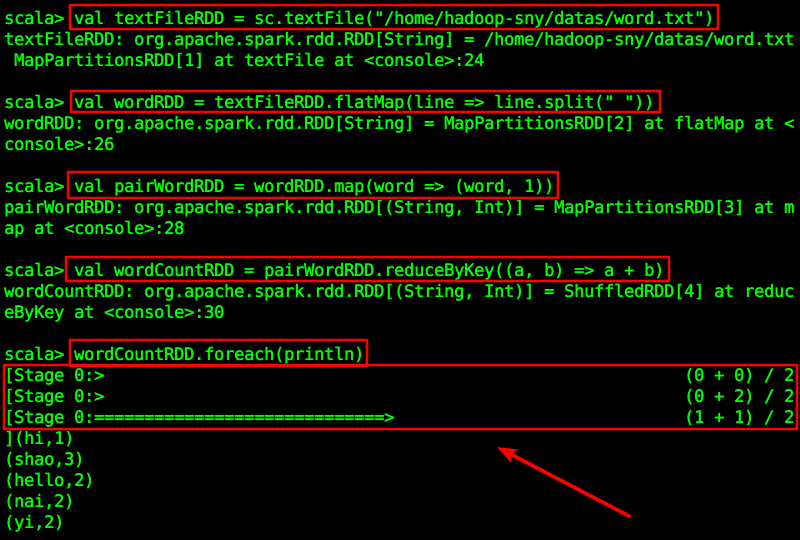
这个例子里,我们用到了很多的算子,但是你会发现,只有执行foreach的时候,才会真正去驱动Spark对整一个作业进行计算,计算是一个阶段(Stage)一个阶段地去执行的,至于 Stage 是怎么划分的,是 Spark 的重点内容,以后再讲。
c. 总结
需要清楚一点,其实转化算子具有Lazy 特性(懒加载),当你写了个程序,上传到我们的集群中执行时,我们的代码会被从上往下扫描,当扫描到转化算子时,其实代码是不会真正去执行的,不会立刻计算结果,仅仅只会记录转换操作应用的目标数据集,只有跑到行动算子时,才会真正去执行,这种设计可以让 Spark 具有更高的效率。
2. 转化算子(transformations算子)
转化算子官网链接跳转:点击跳转
内容比较多,这里只介绍一部分:
【1】map(func):返回通过函数func传递源的每个元素形成的新的分布式数据集。【2】filter(func):返回通过选择func返回true的源的元素形成的新数据集。【3】flatMap(func):类似于map,但是每个输入项可以映射到0个或更多的输出项(所以func应该返回一个Seq而不是一个项)。【4】mapPartitions(func):与map类似,但在RDD的每个分区(块)上单独运行,所以当在类型为T的RDD上运行时,func必须为Iterator <T> => Iterator <U>。【5】mapPartitionsWithIndex(func)与mapPartitions类似,但也提供了一个表示分区索引的整数值的func,所以当在类型T的RDD上运行时,func必须是类型(Int,Iterator <T>)=> Iterator <U>。【6】sample(withReplacement,fraction,seed):使用给定的随机数生成器种子对有数据的一部分数据进行采样或不进行替换。【7】union(otherDataset):返回一个包含源数据集和参数中元素的并集的新数据集。【8】intersection(otherDataset):返回包含源数据集和参数中的元素的新RDD。(即交集)【9】distinct([numTasks])):返回一个包含源数据集的不同元素的新数据集。【10】groupByKey([numTasks]):当对(K,V)对的数据集进行调用时,返回(K,Iterable <V>)对的数据集。注意:如果要分组以便在每个键上执行聚合(如总和或平均值),则使用reduceByKey或aggregateByKey将产生更好的性能。注意:默认情况下,输出中的并行级别取决于父RDD的分区数。可以传递一个可选的numTasks参数来设置不同数量的任务。【11】reduceByKey(func,[numTasks]):当对(K,V)对的数据集进行调用时,返回(K,V)对的数据集,其中使用给定的reduce函数func聚合每个键的值,该函数必须是类型(V,V)=> V.像groupByKey一样,可以通过可选的第二个参数来配置reduce任务的数量。【12】aggregateByKey(zeroValue)(seqOp,combOp,[numTasks]):当(K,V)对的数据集被调用时,返回一个数据集(K,U)对,其中使用给定的组合函数和中性的“零”值对每个键的值进行聚合。允许不同于输入值类型的聚合值类型,同时避免不必要的分配。像groupByKey一样,reduce任务的数量可以通过可选的第二个参数进行配置。【13】sortByKey([ascending],[numTasks]):在K实现有序的(K,V)对的数据集上被调用时,按照布尔升序参数中指定的按升序或降序的顺序返回按键排序的(K,V)对的数据集。【14】join(otherDataset,[numTasks]):当对类型(K,V)和(K,W)的数据集进行调用时,返回一个(K,(V,W))对的数据集与每个键的所有元素对。通过leftOuterJoin,rightOuterJoin和fullOuterJoin支持外连接。【15】cogroup(otherDataset,[numTasks]):当调用类型(K,V)和(K,W)的数据集时,返回一个数据集(K,(Iterable <V>,Iterable W)))元组。这个操作也叫做GroupWith。【16】cartesian(otherDataset):当对类型T和U的数据集进行调用时,返回(T,U)对(所有元素对)的数据集。【17】pipe(command,[envVars]):通过shell命令管理RDD的每个分区,例如一个Perl或bash脚本。 RDD元素被写入到进程的stdin中,并且将其输出的行输出返回为字符串的RDD。【18】coalesce(numPartitions):将RDD中的分区数减少到numPartition。过滤大型数据集后,对于运行操作更有效。【19】repartition(numPartitions):随机重新清理RDD中的数据以创建更多或更少的分区,并在其间平衡。这总是通过网络洗牌所有的数据。【20】repartitionAndSortWithinPartitions(partitioner):根据给定的分区器重新分配RDD,并在每个生成的分区中按其键分类记录。这比调用重新分区,然后在每个分区中排序更有效,因为它可以将排序推入洗牌机器。
3. 行动算子(actions算子)
行动算子官网链接跳转:点击跳转
内容比较多,这里只介绍一部分:
【1】reduce(func):使用函数func(它需要两个参数并返回一个)来聚合数据集的元素。该函数应该是交换和关联的,以便它可以并行计算。【2】collect():在驱动程序中将数据集的所有元素作为数组返回。在通过返回足够小的数据子集的过滤器或其他操作之后,这通常很有用。【3】count():返回数据集中的元素数。【4】first():返回数据集的第一个元素(类似于(1))。【5】take(n):使用数据集的前n个元素返回数组。【6】takeSample(withReplacement,num,[seed]):返回一个具有数据集的num元素的随机抽样的数组,有或没有替换,可选地预先指定随机数生成器种子。【7】takeOrdered(n,[ordered]):使用自然顺序或自定义比较器返回RDD的前n个元素。【8】saveAsTextFile(path):将数据集的元素作为本地文件系统,HDFS或任何其他Hadoop支持的文件系统中的给定目录中的文本文件(或文本文件集)编写。 Spark将在每个元素上调用toString将其转换为文件中的一行文本。【9】saveAsSequenceFile(path):在本地文件系统,HDFS或任何其他Hadoop支持的文件系统的给定路径中,将数据集的元素作为Hadoop SequenceFile写入。这可用于实现Hadoop可写接口的键值对的RDD。在Scala中,它也可以隐式转换为Writable的类型(Spark包括基本类型的转换,如Int,Double,String等)。【10】saveAsObjectFile(path):使用Java序列化以简单的格式写入数据集的元素,然后可以使用SparkContext.objectFile()加载该元素。【11】countByKey():仅适用于类型(K,V)的RDD。返回与(K,Int)对的hashmap与每个键的计数。【12】foreach(func):在数据集的每个元素上运行函数func。这通常用于副作用,例如更新累加器或与外部存储系统进行交互。注意:修改除foreach()之外的累加器以外的变量可能会导致未定义的行为。
0x02 RDD 算子实操
1. 创建 RDD
- 启动 Spark 集群
$SPARK_HOME/sbin/start-all.sh - 启动 Spark Shell
spark-shell --master spark://master:7077 创建一个用于是实操的RDD
val rdd = sc.parallelize(List(1,2,3,3))

2. 转化算子
对常用的转换算子进行操作演示:
【1】map()
rdd.map(x => x + 1).collect()

【2】flatMap()
rdd.flatMap(x => x.to(3)).collect()

解释:对 rdd 里面的每个元素进行 to(3) 操作,将会得到每个元素一直到3的所有元素,如1到3是1,2,3,而2到3是2,3,而3到3是3…以此类似。
【3】filter()
rdd.filter(x => x != 2).collect()
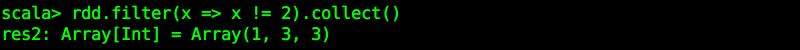
注意:条件为 true 的保留下来!
【4】distinct()
rdd.distinct().collect()

【5】union()
需要对两个RDD进行转换算子操作,所以要先分别创建两个RDD(rdd1、rdd2):
val rdd1 = sc.parallelize(List(1,2,3))val rdd2 = sc.parallelize(List(3,4,5))
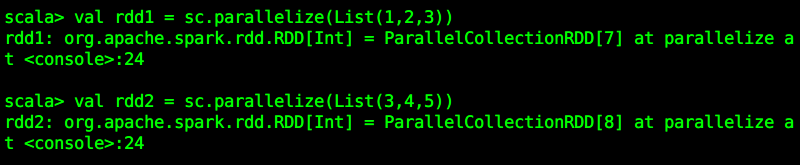
进行相应的操作:
rdd1.union(rdd2).collect()

【6】intersection()
返回rdd1与rdd2的交集。
rdd1.intersection(rdd2).collect()

【7】subtract()
返回rdd1与rdd2的差集,即rdd1减去自己与rdd2相同的数值之后所剩余的结果。
rdd1.subtract(rdd2).collect()

【8】cartesian()
rdd1的值分别对应rdd2的值,即求笛卡尔积,3*3=9个值。
rdd1.cartesian(rdd2).collect()

3. 行动算子
【1】collect()
rdd.collect()

【2】count()
rdd.count()

【3】take()
rdd.take(2)

【4】top()
top(n) 函数会先将数据进行排序(升序:从左向右,逐渐变大),然后从右向左取的前n 个,tuple的话是
按照key进行升序。
rdd.top(2)

【5】countByValue()
可与countByValue做比较,统计value的数量。
rdd.countByValue()
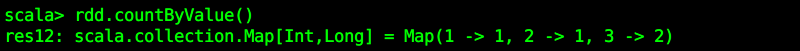
【6】aggregate()
rdd.aggregate((0,0))((x, y) => (x._1 + y, x._2 +1), (x,y) => (x._1 + y._1, x._2 + y._2))

0xFF 总结
- 本次算子比较多,最好都要熟悉,只有熟悉了算子,才能真正去实现我们的业务场景,务必多加练习。
- 加油,努力学习,请查阅本博客更多内容。
作者简介:邵奈一
全栈工程师、市场洞察者、专栏编辑
| 公众号 | 微信 | 微博 | CSDN | 简书 |
福利:
邵奈一的技术博客导航
邵奈一原创不易,如转载请标明出处,教育是一生的事业。

























")

")

")
")



还没有评论,来说两句吧...