hive,order by ,distribute by ,sort by ,cluster by 区别,作用,用法
0 order by 是全局排序,把所有数据放在一个reduce task中排序。sort by是在一个reduce中排序,该reduce的输出有序,是局部有序。distriute by c1 是作用于map输出的结果,把c1的值相同的记录输入到同一个reduce中;如果reduce数目比较少,c1多个不同值的记录会输入到同一个reduce中。
1 distribute by要写在sort by前面,不然报错
2 distribute by c1,c2 sort by c1,c2 = cluster by c1,c2 ,注意distribute by 后面的字段名 与 sort by 后面的字段名相同时才能 使用cluster by。此时是仍然是局部有序,不是全局有序。
3 cluster by c1,c2 默认是升序,且不可指定asc或desc ,不然报错
4 当reduce_num=1时,sort by c1,c2 = order by c1,c2,此时都是在一个reduce中排序,所以此时排序后的结果一致
5 distribute by c1 sort by c2,c3 desc ,如果c1只有一种值,那么此时 = order by c2,c3 desc,因为distribute by c1会把map输出的数据划分到同一个reduce中,然后在这个reduce中按照c2,c3 desc排序,此时与上一条4一致。此时与有多少个reduce task无关,即使手动设置reduce task有多个,但是map的输出只会往一个reduce task中输入,其他reduce task的输入为0
6 测试时,如果想手动设置reduce task有多个,set mapreduce.job.reduce = 2; — 无效。set mapred.reduce.tasks = 2; — 有效
7 [order by]是全局排序,只会启动一个reduce task对所有输出排序,[distribute by/ sort by/cluster by]是根据分区下的数据文件大小计算出启用多少个reduce task,可能会启用多个reduce task.
Hive 中的查询语句说明如下:
[WITH CommonTableExpression (, CommonTableExpression)*]
SELECT [ALL | DISTINCT] select_expr, select_expr, …
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]
测试如下:
1 select * from tmp.test_1031_external_dt ;
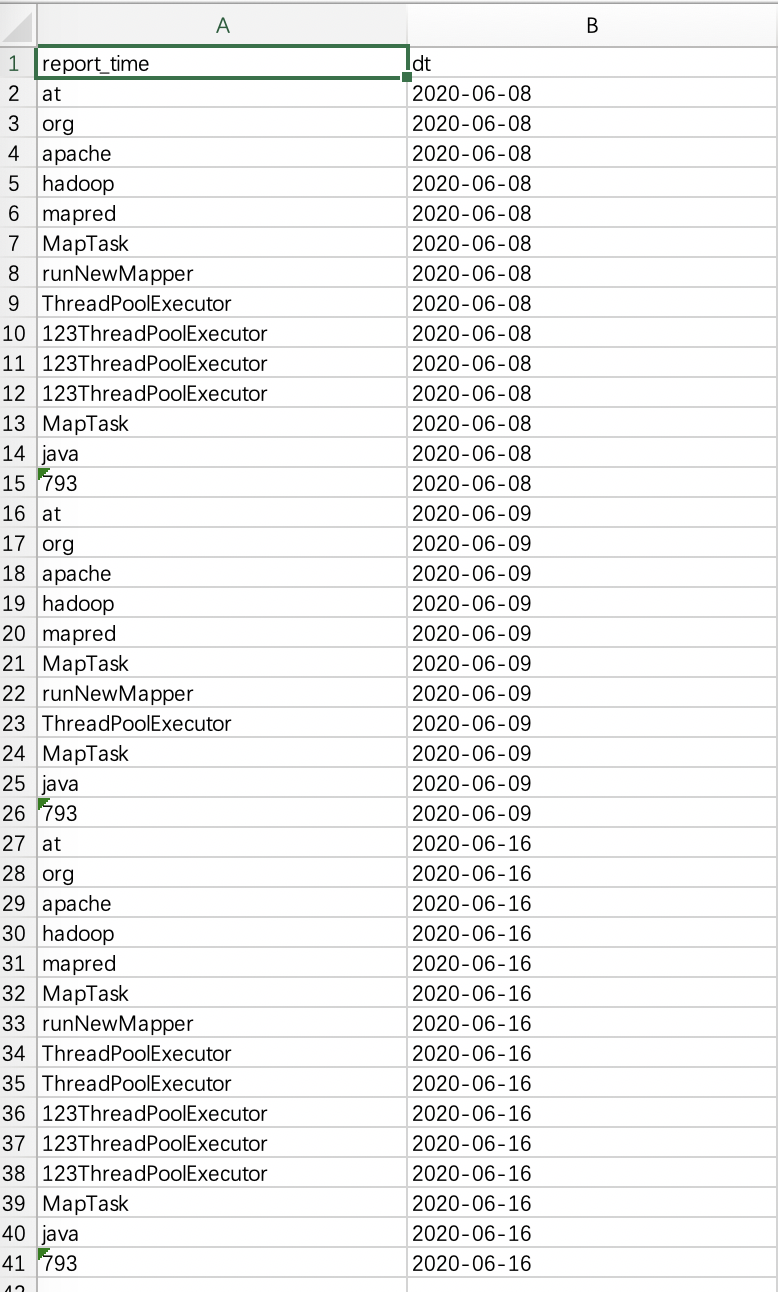
2
select * from tmp.test_1031_external_dt
distribute by dt sort by report_time
-- Stage-1: number of mappers: 3; number of reducers: 1
--结果5
select * from tmp.test_1031_external_dt order by report_time ;
-- Stage-1: number of mappers: 3; number of reducers: 1
--结果6
此时2个结果一样:
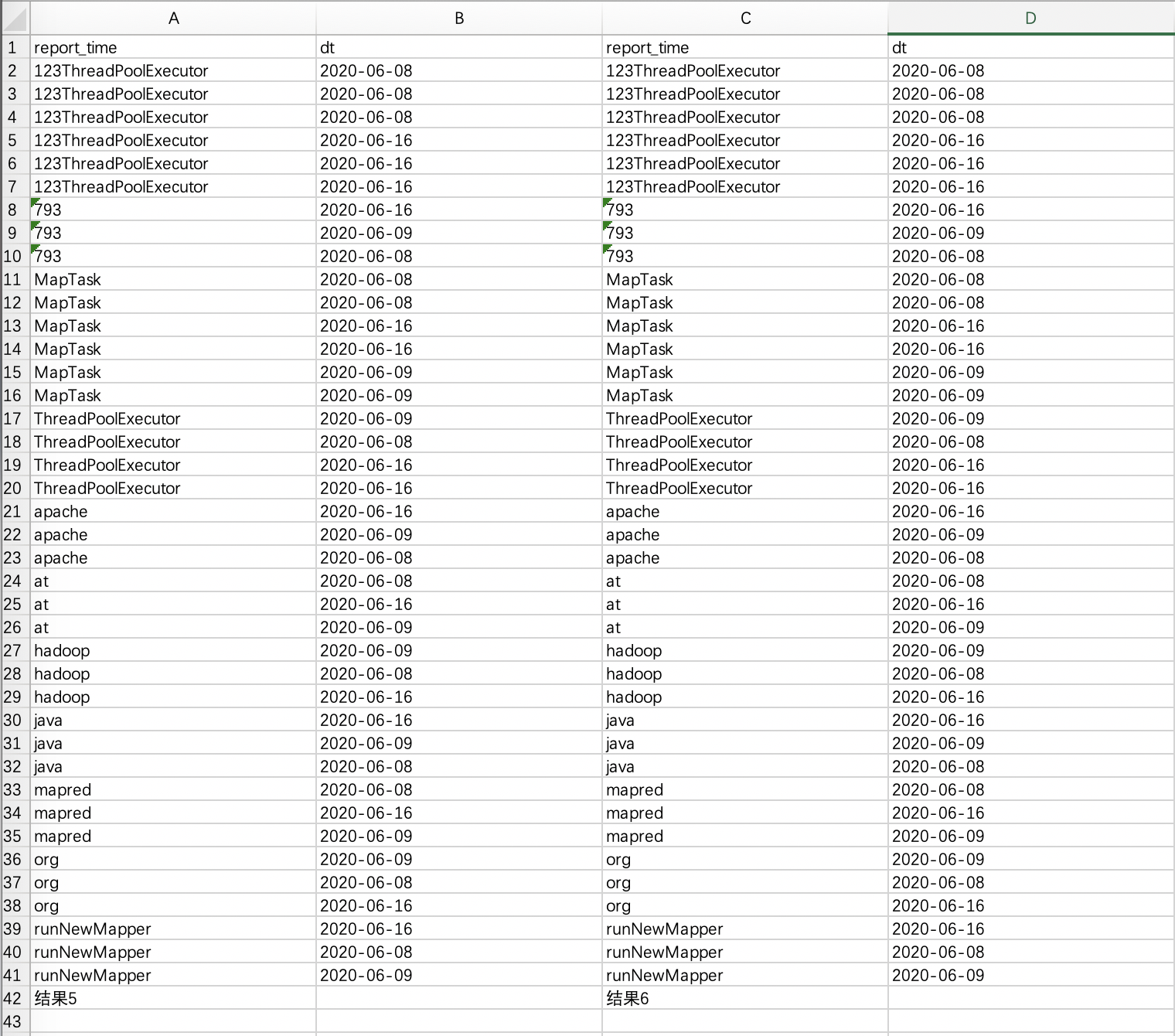
3
-- set mapreduce.job.reduce = 2; — 无效
set mapred.reduce.tasks = 2; — 有效
select * from tmp.test_1031_external_dt sort by report_time ;
-- Stage-1: number of mappers: 3; number of reducers: 2
--结果7,结果第一段从’123ThreadPoolExecutor’升序到’mapred’,第二段是从’123ThreadPoolExecutor’升序到’runNewMapper’
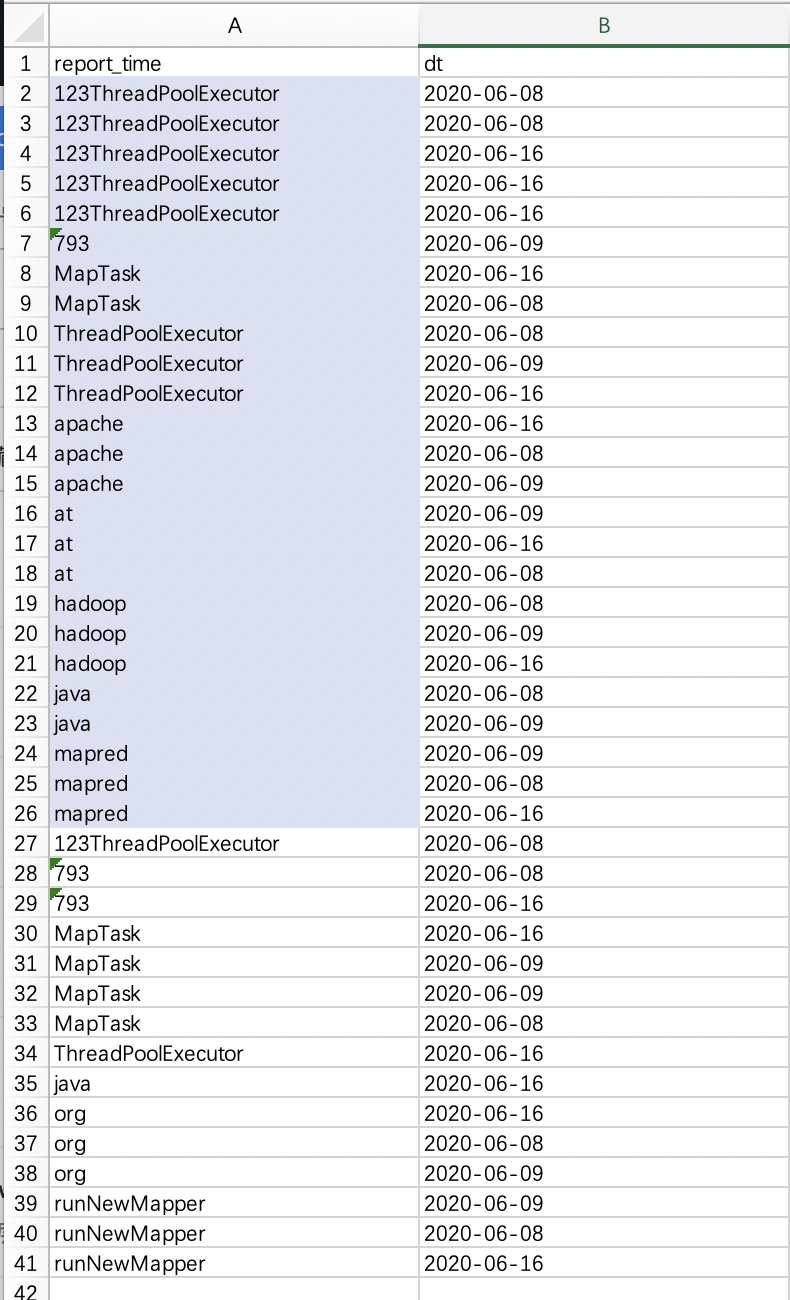
4
set mapred.reduce.tasks = 2; — 有效
select * from tmp.test_1031_external_dt
distribute by dt sort by report_time
--结果8 ,dt=2020-06-08的数 在reduce1 有序,dt=2020-06-16、dt=2020-06-09的数 在reduce2有序,
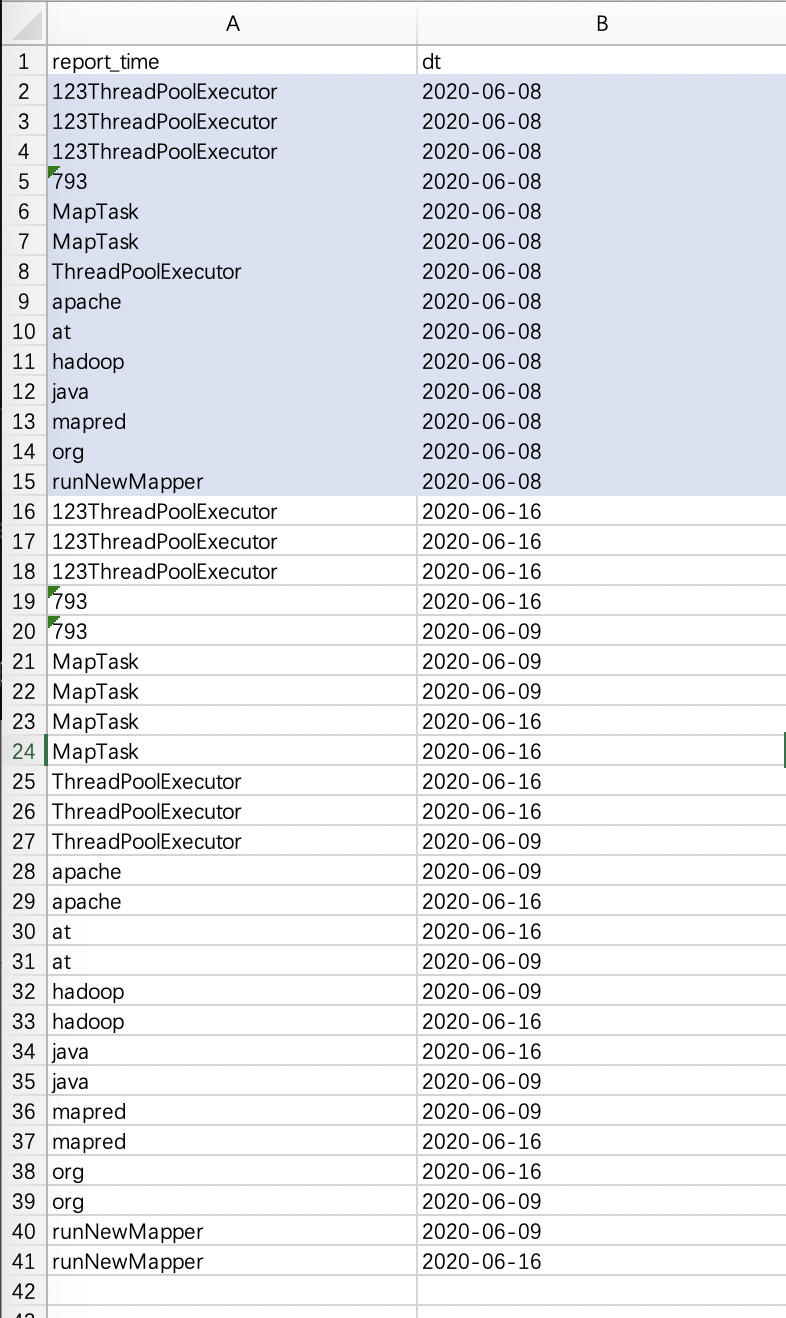
5
select * from tmp.test_1031_external_dt
sort by report_time distribute by dt
-- FAILED: ParseException line 2:20 missing EOF at ‘distribute’ near ‘report_time’
6
set mapred.reduce.tasks = 10; — 有效
select * from tmp.test_1031_external_dt where dt = ‘2020-06-08’
distribute by dt sort by report_time
-- 结果11 ,全局有序,map的输出只会写到一个redeuce中
版本hive2.0.0
参考:
https://zhuanlan.zhihu.com/p/93747613
https://www.jianshu.com/p/fb86b4ac4acf
https://www.jianshu.com/p/1a3625a71118


































还没有评论,来说两句吧...