微服务里的事件驱动数据管理
微服务下的分布式数据管理问题
单体应用程序通常具有单个关系数据库。 使用关系数据库的主要好处是应用程序可以使用ACID事务,这提供了一些重要的保证:
- 原子性–原子地进行更改
- 一致性–数据库状态始终是一致的
- 隔离–即使事务是同时执行的,看起来它们还是串行执行的
- 持久性–事务一旦提交,便不会撤消
有了这些,应用程序就可以可以很容易的地开启事务,执行更改(插入,更新和删除)多行的操作并提交事务。
使用关系数据库的另一个巨大好处是它提供了SQL,这是一种丰富,声明式和标准化的查询语言。我们可以轻松地编写将多个表中的数据合并在一起的查询。然后,RDBMS query planner确定执行查询的最佳方法。不必担心底层细节,例如如何访问数据库。而且,由于您所有应用程序的数据都在一个数据库中,因此查询起来很容易。
然后,当我们转向微服务架构时,数据访问变得更加复杂。这是因为每个微服务拥有的数据是该微服务专用的,并且只能通过其API访问。封装数据可确保微服务松散耦合,并且可以彼此独立发展。如果多个服务访问相同的数据,则schema更新需要对所有服务协调更新。
更糟糕的是,不同的微服务通常使用不同种类的数据库。现代应用程序存储和处理各种数据,而关系数据库并不总是最佳选择。对于某些用例,特定的NoSQL数据库可能具有更方便的数据模型,并提供更好的性能和可伸缩性。例如,对于存储和查询文本的服务来说,使用诸如Elasticsearch之类的文本搜索引擎是有意义的。同样,存储社交图数据的服务可能应使用图数据库,例如Neo4j。因此,基于微服务的应用程序经常使用SQL和NoSQL数据库的混合,即所谓的多语言持久性方法。
用于数据存储的分区,多语言持久性架构具有许多优点,包括松散耦合的服务以及更好的性能和可伸缩性。但是,它确实带来了一些分布式数据管理方面的挑战。
第一个挑战是如何实现在多个服务之间保持业务transaction的一致性的。要了解为什么会出现问题,我们可以来看一个在线B2B商店的示例。客户服务维护有关客户的信息,包括他们的信用额度信息。订单服务负责管理订单,并且必须验证新订单没有超出客户的信用额度。如果用单体应用程序实现此功能的话,订单服务可以简单地使用ACID transaction来检查可用的信用额度并创建订单。
相反,在微服务体系结构中,ORDER和CUSTOMER表是它们各自的服务专用的,如下图所示。
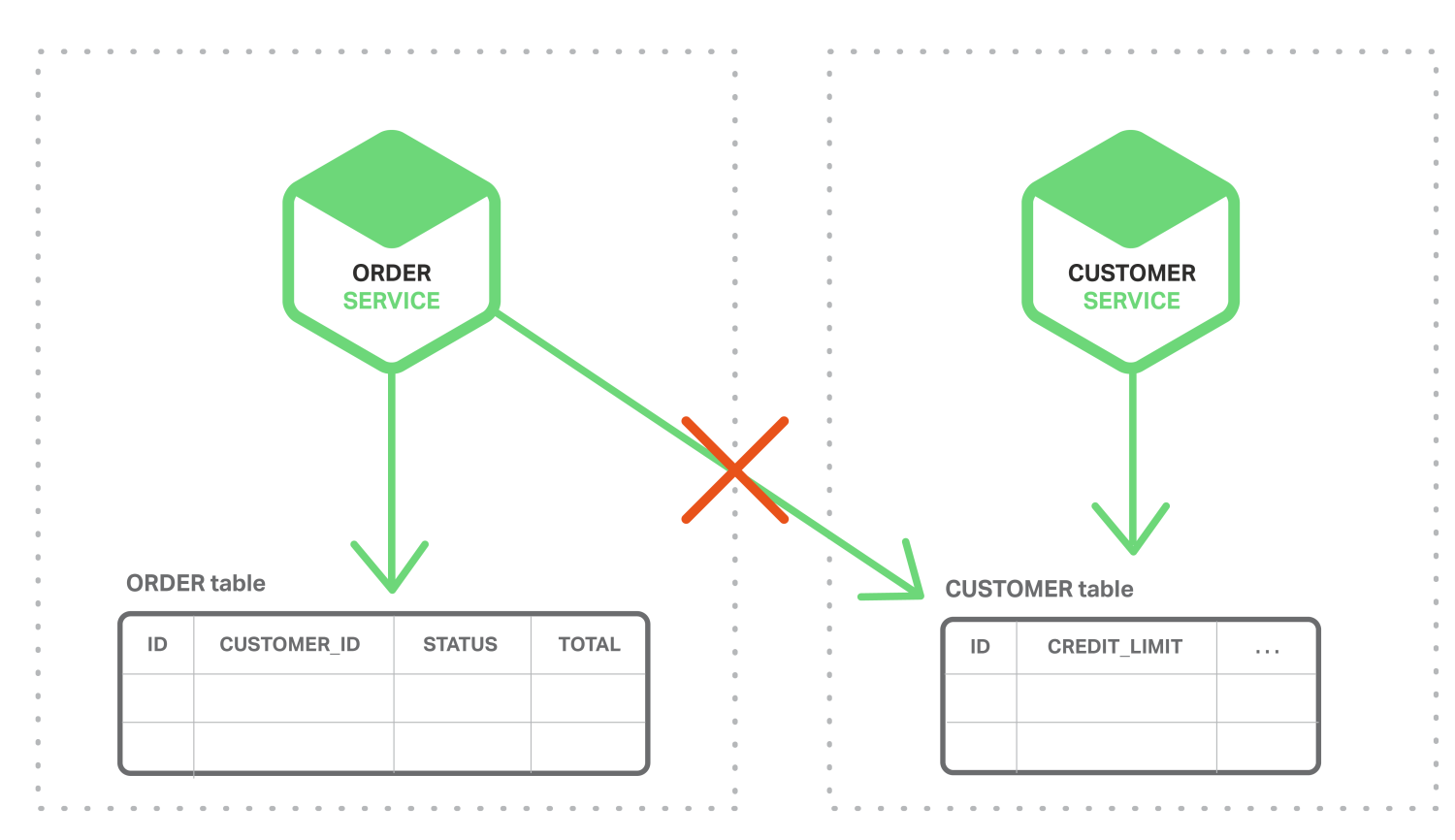
订单服务无法直接访问CUSTOMER表。它只能使用客户服务提供的API。订单服务可能会使用分布式事务,也称为两阶段提交(2PC)。但是,在现代应用中2PC通常不是可行的选择。 CAP定理要求您在可用性和ACID样式一致性之间进行选择,而可用性通常是更好的选择。而且,许多现代技术,例如大多数NoSQL数据库,都不支持2PC。维护服务和数据库之间的数据一致性至关重要,因此我们需要另一个解决方案。
第二个挑战是如何实现从多个服务检索数据的查询。例如,假设应用程序需要显示客户及其最近的订单。如果订单服务提供了用于检索客户订单的API,那么您可以使用应用程序侧联接来检索此数据。该应用程序从客户服务中检索客户,并从订单服务中检索客户的订单。但是,假设Order Service仅支持按主键查找订单(也许它使用的NoSQL数据库仅支持基于主键的检索)。在这种情况下,没有直接的方法来检索所需的数据。
事件驱动架构
对于许多应用程序而言,解决上述问题的方案是使用事件驱动的体系结构。 在这种体系结构中,微服务会在某些操作执行时(例如更新业务实体)发布事件publish event。 其他微服务订阅则这些事件。 当微服务收到事件时,它就更新自己的业务实体,这可能会发布更多事件。
我们可以使用事件来实现跨多个服务的业务交易。 交易的transactions 包括一系列步骤。 每个步骤都包含一个微服务对该微服务更新业务实体并发布触发下一步的事件。 下面的图表序列显示了在创建订单时如何使用事件驱动的方法来检查可用信用。 微服务通过消息代理交换事件。
- 订单服务order service创建状态为NEW的订单,并发布Order Created事件。
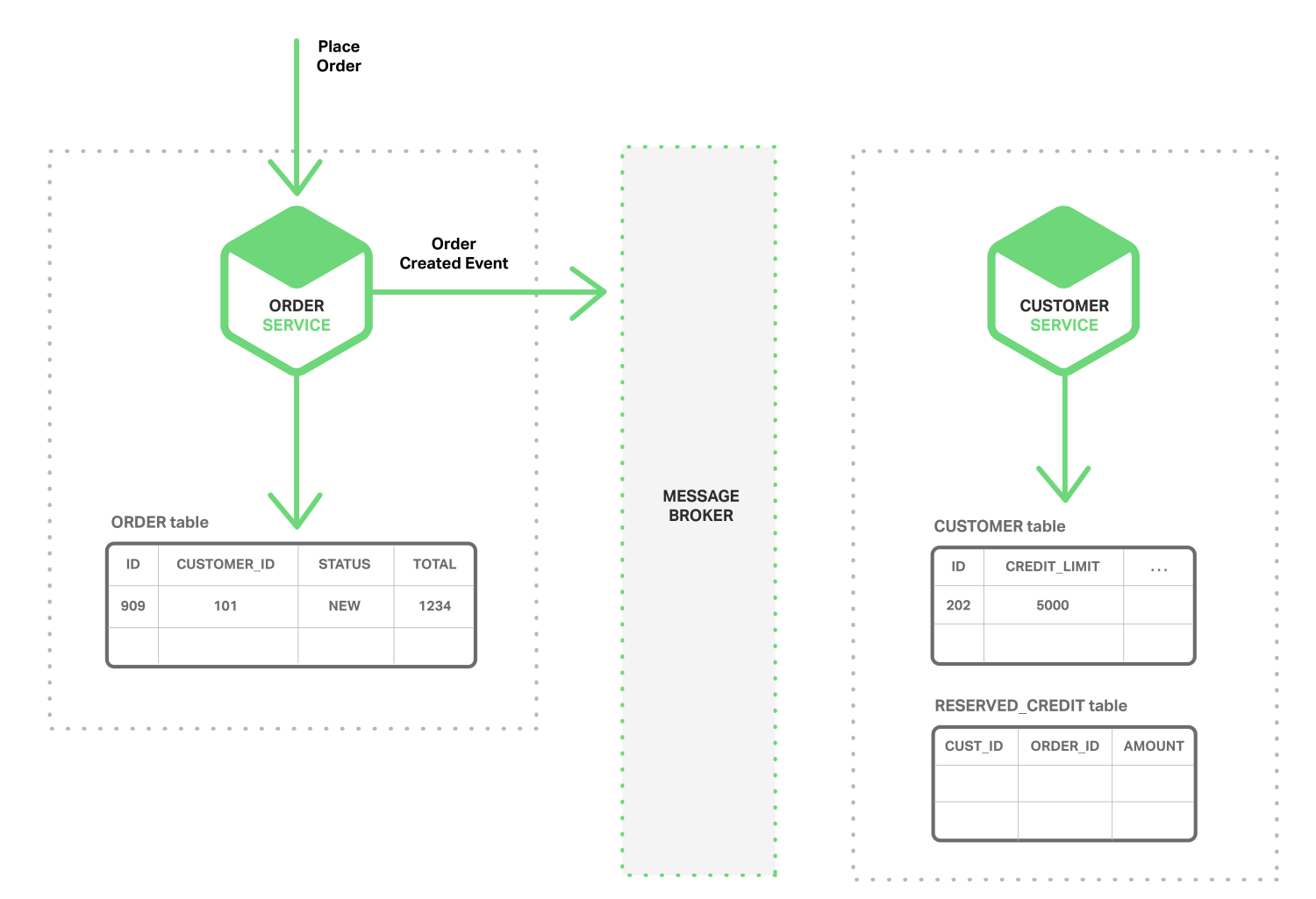
- 客户服务customer service监听消费“Order Created”事件,为订单保留信用,并发布“Credit Reserved”事件。
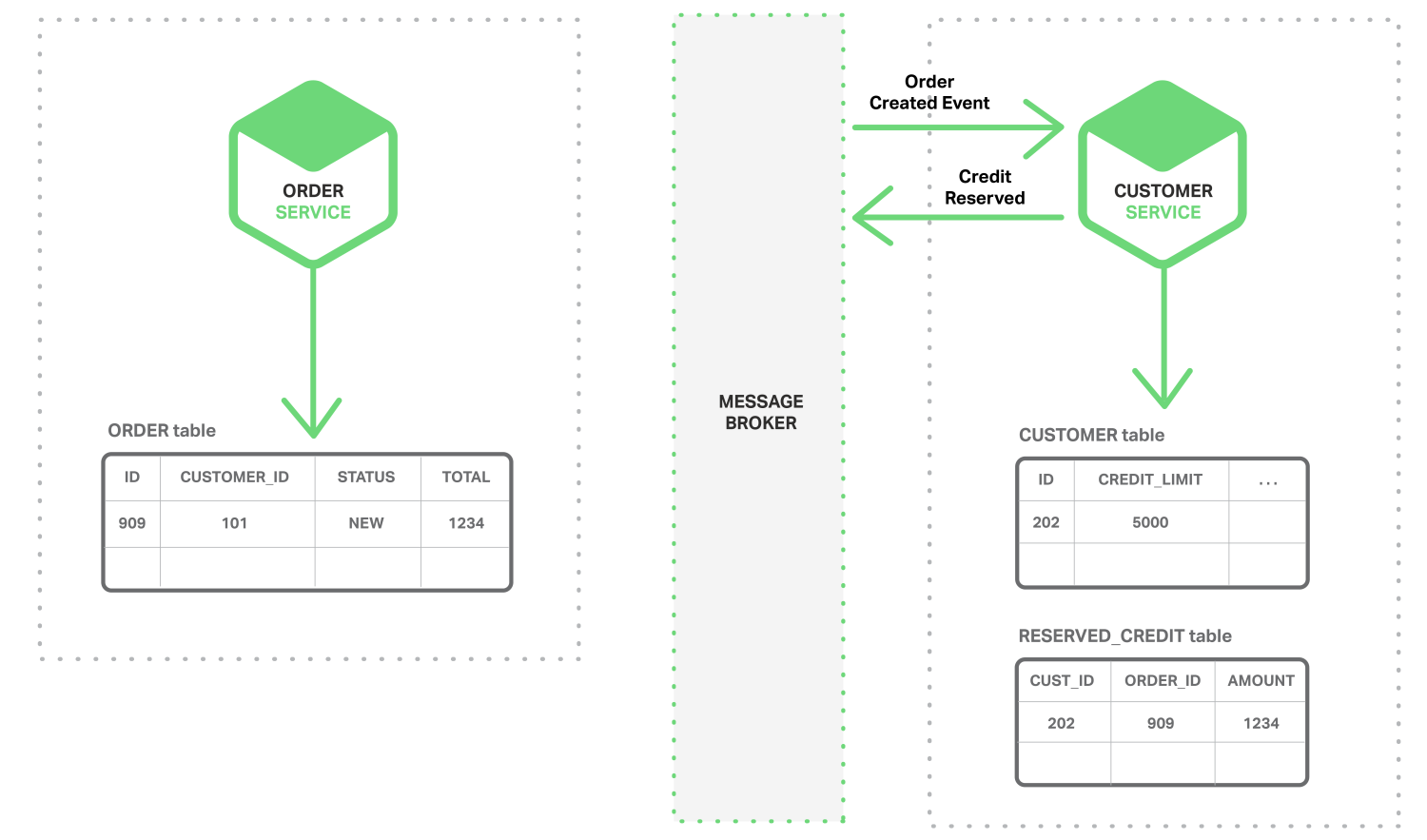
- 订单服务consume “Credit Reserve”事件,并将订单状态更改为“open”
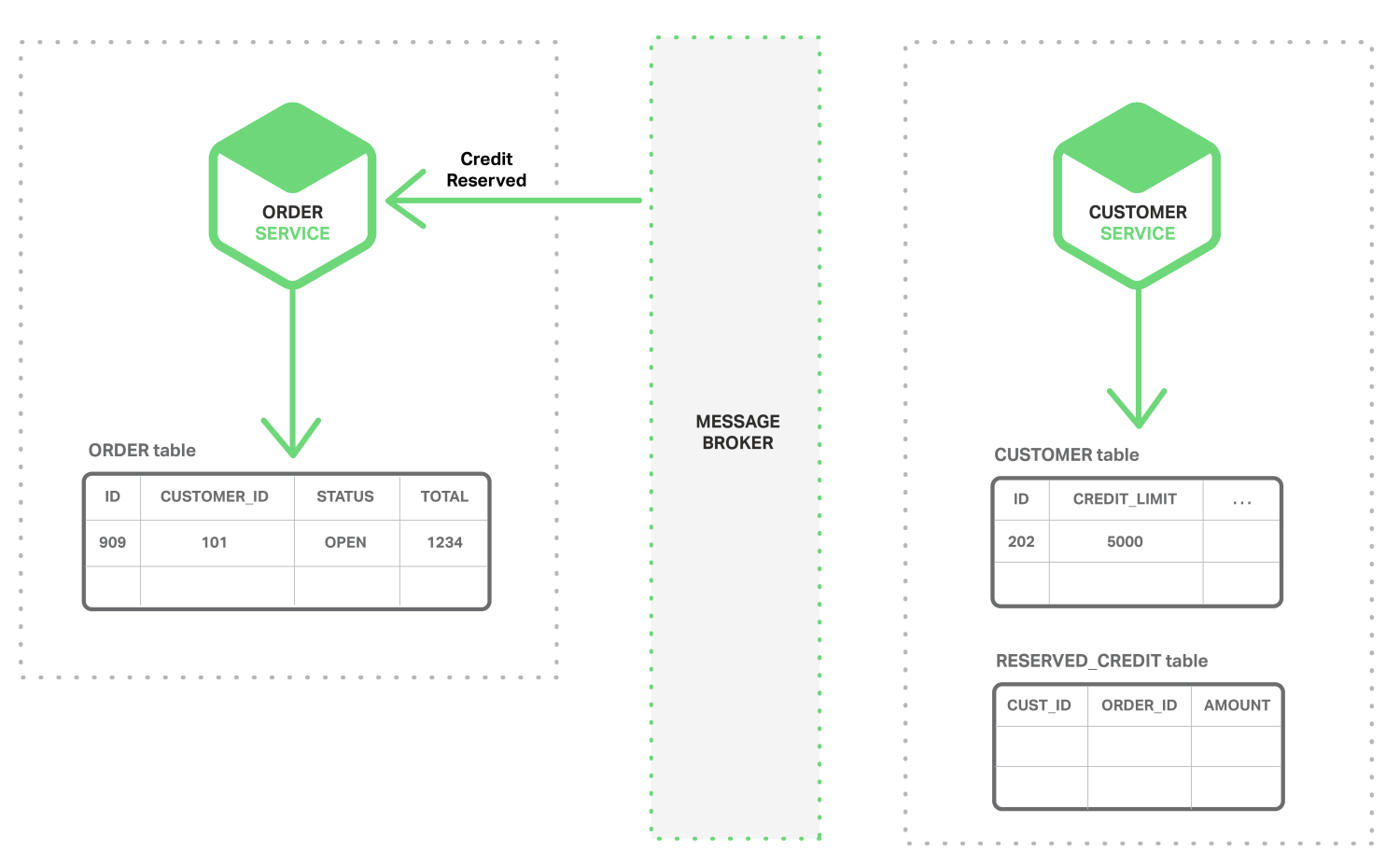
更复杂的情况下可能会涉及其他步骤,例如在上述场景当中在检查客户信用的同时可以保留库存。
假设每个服务保证自动更新数据库并发布事件,并且Message Broker保证事件至少被传递一次,则我们就可以实现跨多个服务的业务交易。 重要的是要注意,这些操作不满足ACID transactions。 它们提供的保证要弱得多,例如系统可能只会保证最终的一致性。 该交易模型已被称为BASE模型。
您还可以使用事件来维护实例化视图,这些视图预先加入了多个微服务拥有的数据。 维护视图的服务订阅相关事件并更新视图。 例如,维护客户订单视图的客户订单视图更新程序服务订阅由客户服务和订单服务发布的事件。
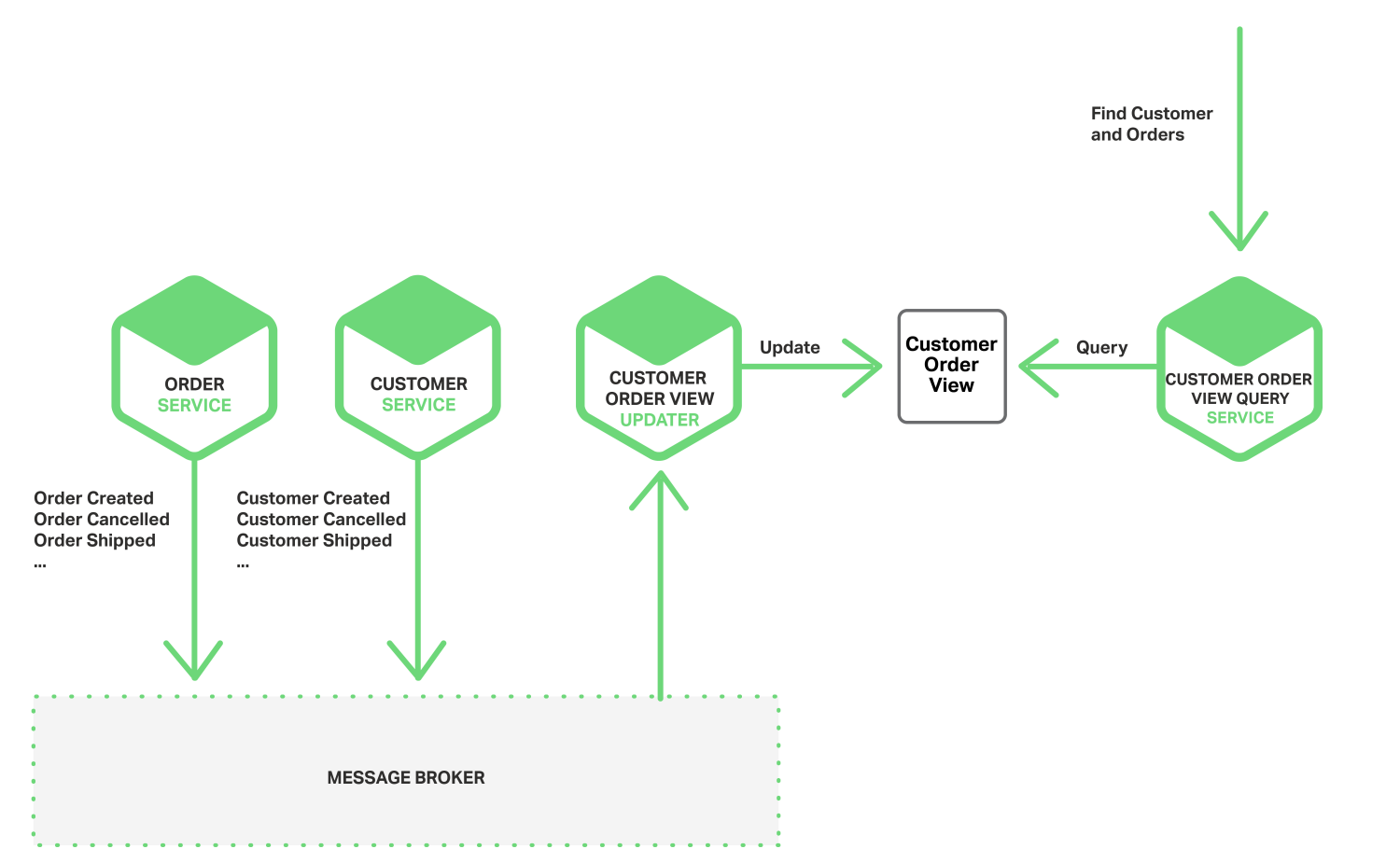
客户订单视图更新程序服务收到客户或订单事件时,将更新客户订单视图数据存储。您可以使用文档数据库(例如MongoDB)实现客户订单视图,并为每个客户存储一个文档。客户订单视图查询服务通过查询客户订单视图数据存储来处理对客户和最近订单的请求。
事件驱动的体系结构有这样几个优点和缺点。好处是首先,它使跨多个服务的事务的实现成为可能,并提供最终的一致性。另一个好处是它还使应用程序能够维护实例化视图。一个缺点是,编程模型比使用ACID事务时更复杂。通常,我们必须实现补偿事务以从应用程序级故障中恢复;例如,如果信用检查失败,则必须取消订单。此外,应用程序必须处理不一致的数据。这是因为各个transaction之间用到的数据对彼此来说是可见的。如果应用程序从尚未更新的实例化视图中读取数据,则会看到不一致之处。另一个缺点是事件的订阅方必须检测并忽略重复的事件。
实现原子性
在事件驱动的体系结构中,还存在原子更新数据库并发布事件的问题。 例如,订购服务必须在ORDER表中插入一行并发布订购创建事件。 这两个操作必须保证原子性。 如果服务在更新数据库之后但在发布事件之前崩溃,则系统会变得不一致。 确保原子性的标准方法是使用涉及数据库和Message Broker的分布式事务。 但是,由于上述原因以及CAP定理,这正是我们不希望做的
使用本地事务发布事件
一种实现原子性的方法是,应用程序使用仅涉及本地事务的多步骤过程来发布事件。 关键诀窍是在存储业务实体状态的数据库中创建一个EVENT表,该表的作用就是充当消息队列。 应用程序开始(本地)数据库事务,更新业务实体的状态,将事件插入EVENT表,然后提交事务。 提供一个单独的应用程序线程或进程查询EVENT表,将事件发布到Message Broker,然后使用本地事务将事件标记为已发布published的状态。 下图是该设计的示例。
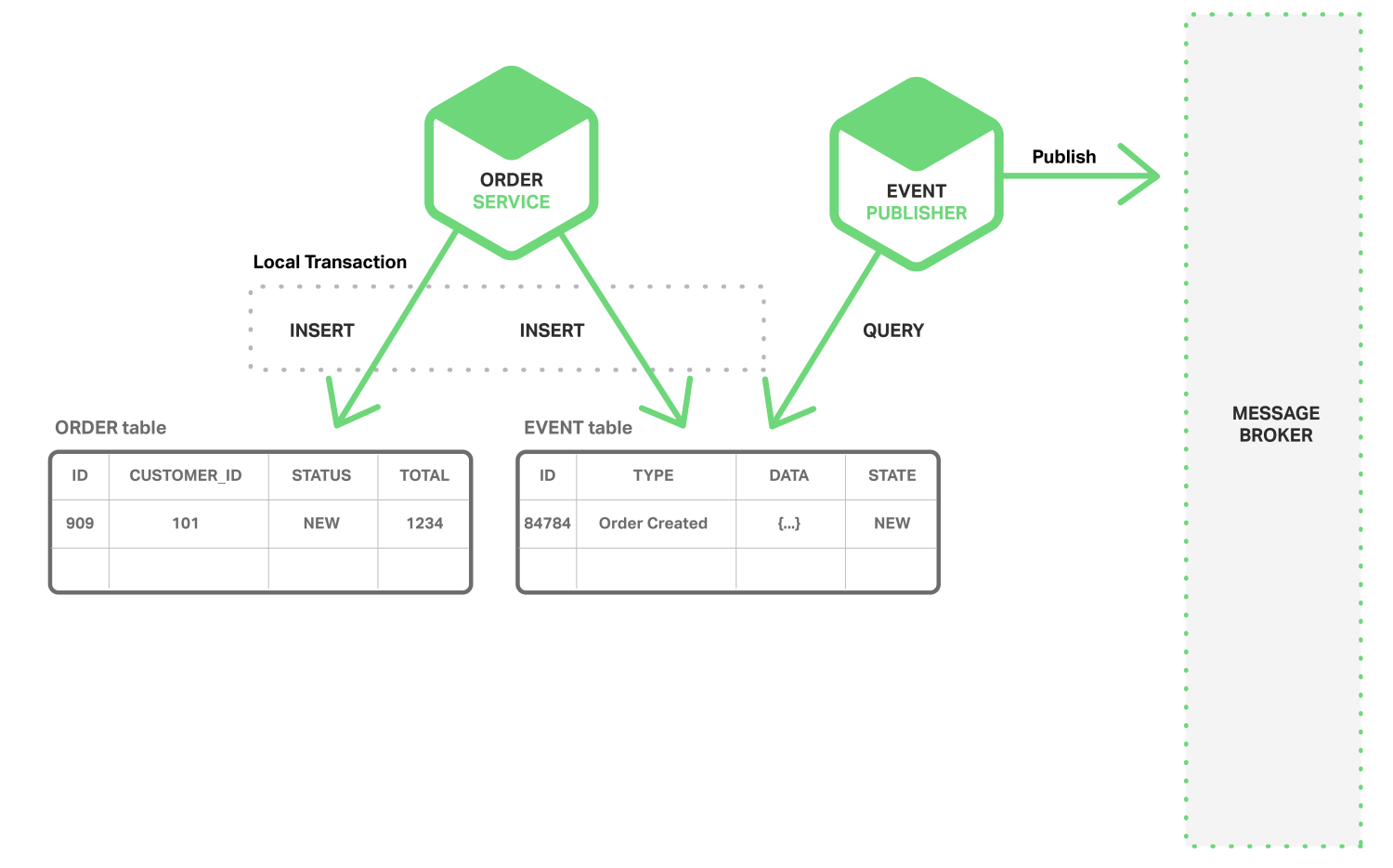
上图做的事情是:订单服务将一行插入到ORDER表中,并将订单创建事件插入到EVENT表中。事件发布者线程或进程在EVENT表中查询未发布的事件,发布事件,然后更新EVENT表以将事件标记为已发布。
这种方法有这样几个优缺点。一个好处是,它可以确保每次更新都发布一个事件,而无需依赖2PC。此外,该应用程序还发布业务级别的事件,从而无需解析它们。这种方法的一个缺点是,由于开发人员必须记住要发布事件,因此它很容易出错。这种方法的局限性在于,在使用某些NoSQL数据库时难以实施,因为NoSQL数据库它们的事务和查询功能有限。
通过让应用程序使用本地事务来更新状态和发布事件,该方法消除了对2PC的需求。现在让我们看一下一种通过使应用程序简单地更新状态来实现原子性的方法。
挖掘数据库事务日志
在没有2PC的情况下实现原子性的另一种方法是,事件由挖掘数据库事务或提交日志的线程或进程发布。 该应用程序更新数据库,从而将更改记录在数据库自身的事务日志中。 事务日志挖掘器线程或进程读取事务日志并将事件发布到Message Broker。 下图是设计说明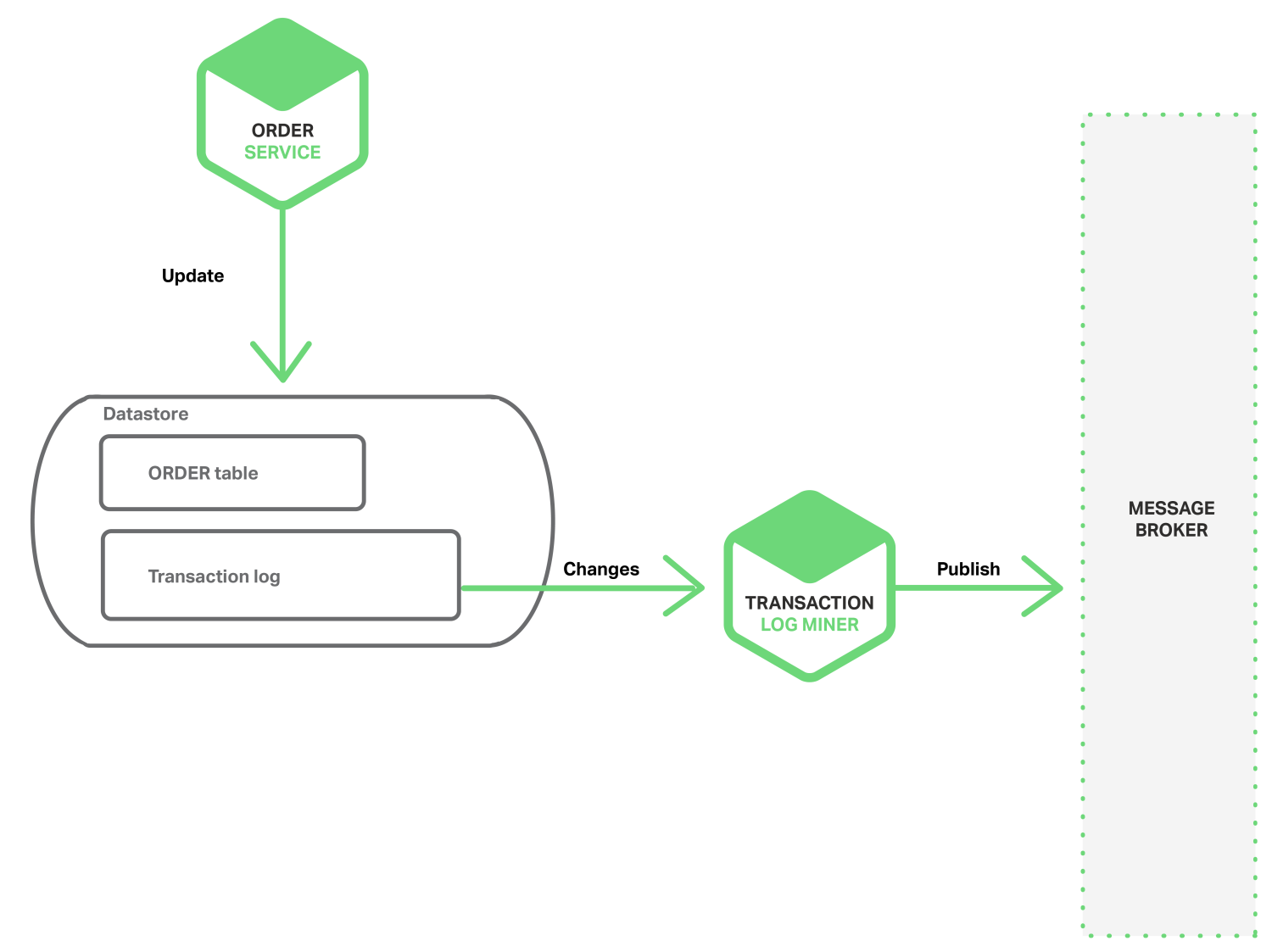
这种方法的一个示例是开源LinkedIn Databus项目。 Databus挖掘Oracle事务日志并发布与更改相对应的事件。 LinkedIn使用Databus来保持各种派生数据存储与记录系统一致。
另一个示例是AWS DynamoDB中的流机制,这是一个托管的NoSQL数据库。 DynamoDB流包含过去24小时内对DynamoDB表中的项目进行的按时间顺序排列的更改(创建,更新和删除操作)序列。应用程序可以从流中读取这些更改,例如,将其作为事件发布。
事务日志挖掘具有一些优缺点。一个好处是,它保证了每次更新都可以发布事件,而无需使用2PC。事务日志挖掘还可以通过将事件发布与应用程序的业务逻辑分开来简化应用程序。一个主要的缺点是事务日志的格式是每个数据库专有的,甚至可以在数据库版本之间进行更改。同样,要从事务日志中记录的相对底层的更新中对更高层业务事件进行转化也是很难的。
事务日志挖掘通过让应用程序执行一件事来消除对2PC的需求:更新数据库。现在让我们看一下消除更新并仅依赖事件的另一种方法。
使用事件源event sourcing
通过使用不同的,以事件为中心的方法来持久化业务实体,事件无需2PC就可以实现原子性。 应用程序不再存储业务实体的当前状态,而只是存储一系列状态更改事件。 应用程序通过重播事件来重建实体的当前状态。 只要业务实体的状态发生变化,就会在事件列表中附加一个新事件。 由于保存事件是单个操作,因此它本质上是原子的。
我们可以用Order实体为例,来看一下事件源如何工作。 在传统方法中,每个订单都会存储映射到order service的ORDER表中的一行以及例如ORDER_LINE_ITEM表中的行。 但是,在使用事件源event sourcing时,订单服务order service以其状态更改事件的形式存储订单:Created已创建,approved已批准,shipped已发货,cancelled已取消。 每个事件都包含足够的数据来重构订单状态。
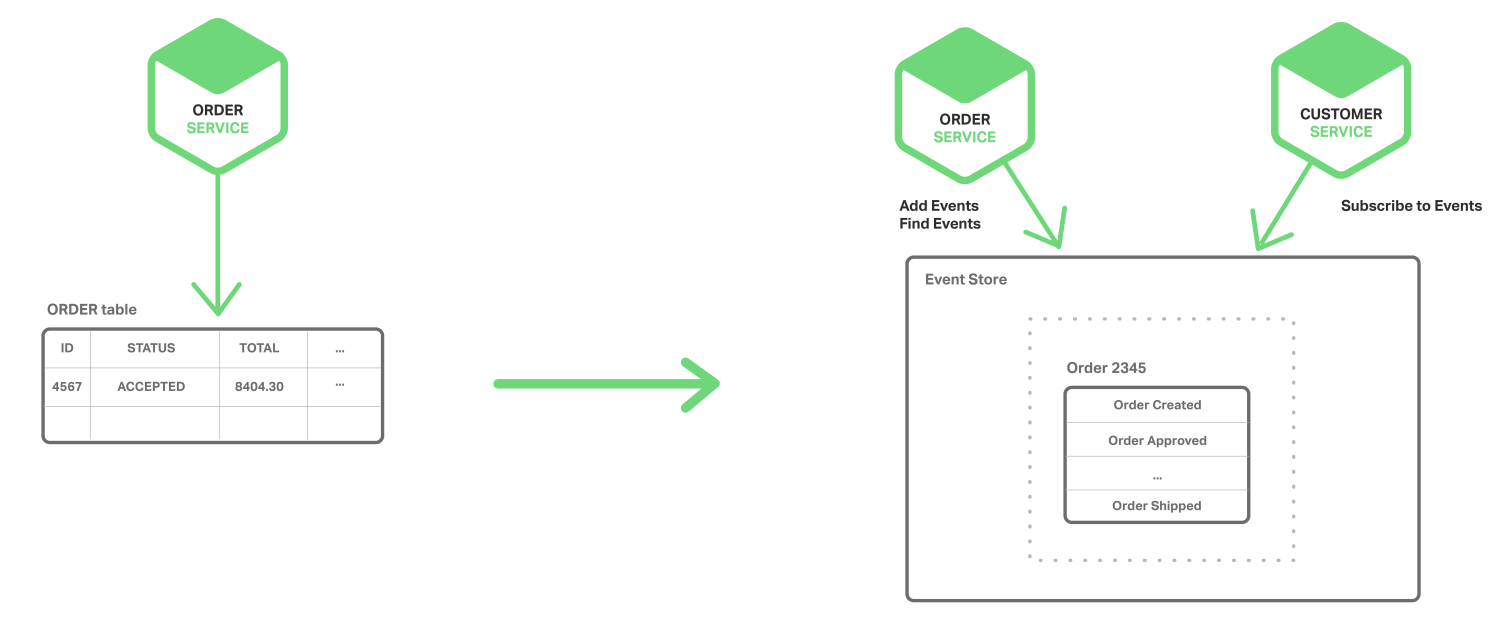
事件存储在事件的存储位置中,事件的存储位置就是是事件的数据库。这里的商城系统具有用于添加和检索实体事件的API。在我们之前描述的体系结构中,事件存储的行为也类似于消息代理。它提供了使服务能够订阅事件的API。事件存储将所有事件传递给所有感兴趣的订户。事件存储是事件驱动的微服务体系结构的核心。
事件源有几个好处。它解决了实现事件驱动的体系结构中的关键问题之一,并使得在状态改变时可靠地发布事件成为可能。它解决了微服务体系结构中的数据一致性问题。另外,由于它保留事件而不是域对象,因此它主要避免了对象关系阻抗不匹配的问题。事件源还提供了对业务实体所做的更改的100%可靠的审核日志,并使得可以实施临时查询来确定实体在任何时间点的状态。事件源的另一个主要优点是您的业务逻辑由交换事件的松散耦合的业务实体组成。这使得从单片应用程序迁移到微服务架构变得容易得多。
事件源也有一些缺点。这是一种不同且陌生的编程风格,因此存在学习曲线。事件存储区仅直接支持通过主键查找业务实体。您必须使用命令查询职责隔离(CQRS)来实现查询。其结果是,应用程序必须处理最终一致的数据。
我们再以一个银行账户的例子来看一下event sourcing的方式:
假设银行账户被我们抽象为实体Accoun,它有几个方法:create(), deposit(), withdraw(),分别用于处理新建账户、账户存款和取款的操作
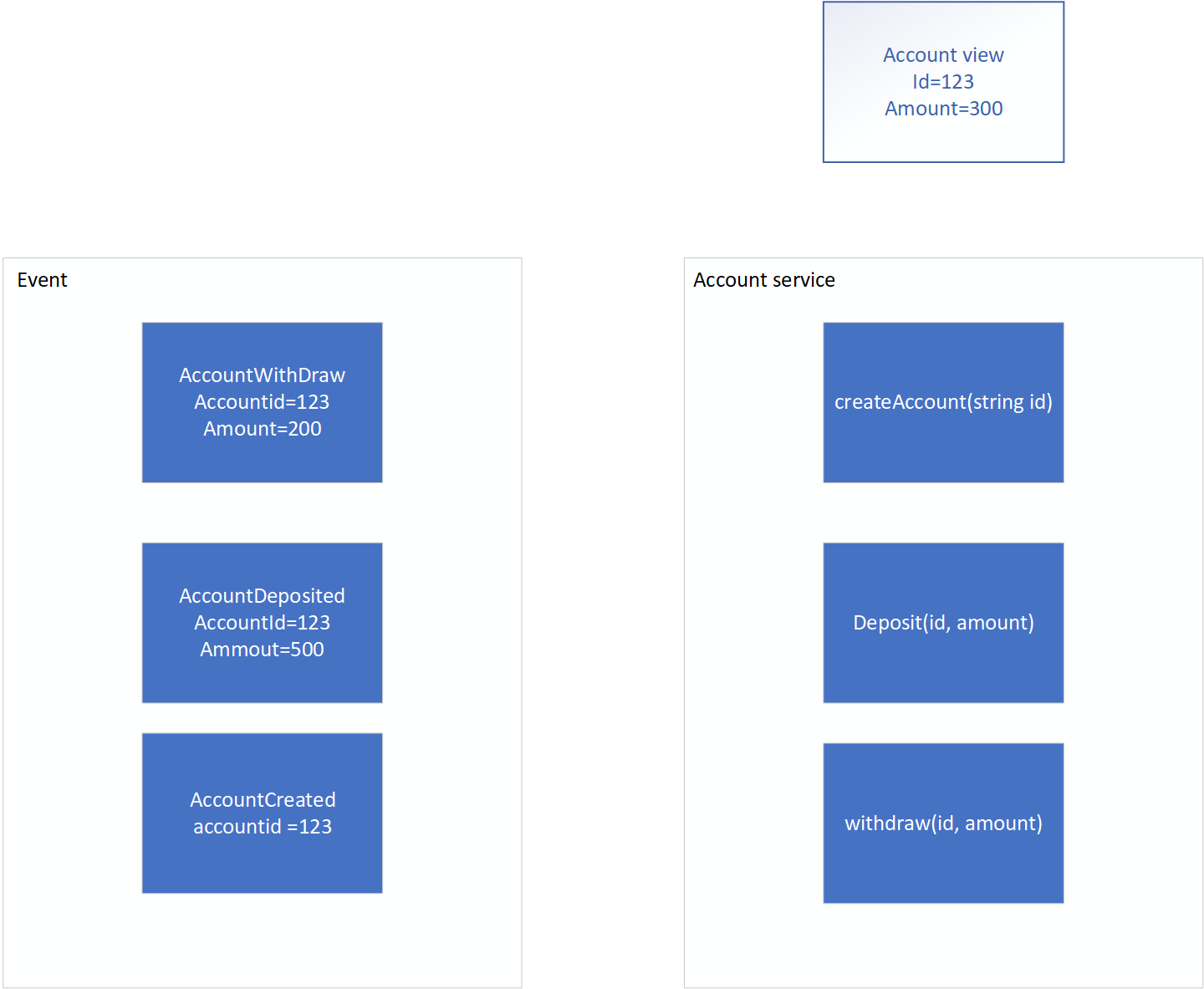
左边的是事件,它是一个事件的流,根据用户请求或者从其他任何可以发布事件的地方产生,甚至也可以是account service自己发出的事件。在个这里例子当中,有3个事件:AccountCreated创建账户, AccountDeposited存钱, AccountWithdrawed取钱,分别用于在收到账户创建的事件,存款的事件和取款的事件时执行相应的操作。
右边的就是这个Account对象处理完左边的4个事件以后,最新的数据状态。具体的处理过程就是:
- 系统触发了一个新建账户的事件
AccountCreated,Account服务调用createAcount的方法来处理这个事件,系统新建一个Account对象,调用createAccount()方法根据生成一个id为123的账户,我们同时定义初始账户金额为0。 - 第二个事件是
AccountDeposited事件,事件里指明对id是123的account执行存钱500的曹组,account service处理该事件并且调用Deposit方法执行增加的余额的操作,更新了账户余额。 - 第三个事件是取款事件,又更新了一次余额,取出了200块钱。
- 最后,这个账户的余额是300。
同时,上面的这些事件需要持久保存在数据库或其他地方,而account的数据状态却不需要保存,我们只是在需要获得account当前的数据状态的时候,通过这个account相关的事件,调用他们的处理函数,重新生成当前状态。当然,每次都这样调用处理函数势必会影响效率,因为它需要从数据库中取得所有这个account的事件,然后依次调用处理函数。所以一般我们可以把这个account的最新状态,以一种视图的方式保存在数据库中,也就是右边的上面account view所保存的东西。
上面这个方式和过程,就是我们说的Event Sourcing,也就是以事件为源的处理模式。
总的来看: event sourcing有下面的这些特点
- 整个系统以事件为驱动,所有业务都由事件驱动来完成。
- 系统的数据以事件为基础,事件要保存在某种存储(数据库)上。
- 业务数据只是一些由事件产生的视图,不一定要保存到数据库中
总结
在微服务架构中,每个微服务都有自己的私有数据存储。 不同的微服务可能使用不同的SQL和NoSQL数据库。 尽管此数据库体系结构具有显着的优势,但它带来了一些分布式数据管理方面的挑战。 第一个挑战是如何实现在多个服务之间保持一致性的业务交易。 第二个挑战是如何实现从多个服务检索数据的查询。
对于许多应用程序,解决方案是使用事件驱动的体系结构。 实现事件驱动的体系结构的一个挑战是如何原子更新状态以及如何发布事件。 有几种方法可以做到这一点,包括将数据库用作消息队列,事务日志挖掘和事件源。

























")


")
")
![[机器学习基础][台大林轩田]机器学习概念](https://image.dandelioncloud.cn/images/20230808/0e7dd15afa194195b5143a2a8bf2e014.png "[机器学习基础][台大林轩田]机器学习概念")



还没有评论,来说两句吧...