Mysql limit 分页机制和优化实例
MySQL limit 操作常用于程序中的分页,但是如果你没有了解过limit的机制和相关优化原理,一旦数据量上升,程序的性能将会惨不忍睹,所以下面总结几种mysql关于limit优化实例,每个实例后对应都会有演示。(演示的数据来自15年暑期实习的p2p流量数据,表数据量约300W行)
1、sql中会范的错误
[sql] view plain copy


- select XXX from tableA limit 1000000,10;
上面 的语句是取1000000后面的10条记录,但是这样会导致mysql将1000000之前的所有数据全部扫描一次,大量浪费了时间。截图是我扫描100W数据花费的时间,大概是2S多
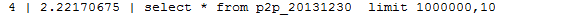
这在程序中肯定是不可忍受的。
对于mysql,优化limit最重要的一点就是尽量先用主键id的索引到起始位置,然后再截取需要的行数。
2、优化方式
(1)使用记录主键的方式进行优化
limit最大的问题在于要扫描前面不必要的数据,所以可以先对主键的条件做设定,然后记录住主键的位置再取行。
[sql] view plain copy
- select * from p2p_20131230 where main_id > 1000000 order by main_id limit 10;
这样执行的结果如下所示, 比没有优化前提升了很多倍。
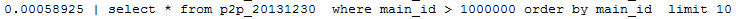
(2)使用子查询进行查询:
[sql] view plain copy
- select * from p2p_20131230 where main_id >= (select main_id from p2p_20131230 limit 1000000,1) limit 10;
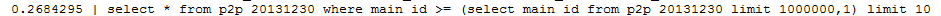
(3) 使用between关键字
如果在主键id是有序不变的情况下,还可以手动计算between的前后两个条件进行查询,这里我就不上代码了。
总结一下,上面的集中方法都是利用mysql的主键索引进行优化,当然应用中通常很难直接获得索引,基本上都是格局where后的某个条件,这个时候就可以先用条件查询出主键id,然后再用上述方式获取结果集即可。


























输出null的问题")

")
Mybatis中的#和$的区别")




还没有评论,来说两句吧...