并发底层实现原理
为什么引入并发
我们引入并发的目的是为了提高CPU的利用率,比如在拥有多核的CPU中,如果程序以串行的方式执行,那么并不能利用其他核。其次,我们的程序中往往需要进行大量的I/O操作,而CPU给I/O接口DMA发出信号后,便处于空闲的状态,此时CPU并不能得到利用。所以通过并发,可以让我们更加充分的利用CPU,提高其利用率,提高程序的运行速度。
并发带来的问题
凡事都具有两面性,引入并发虽然可以提高CPU的利用率,但是如果不解决其带来的副作用,只会使我们的程序不安全,错误,事倍功半。 想必大家都敲过`i++`的代码,在多线程的环境下,执行结果并不符合我们的预期,这便是并发所带来的问题。 我们知道CPU为了提高其运算速度,避免频繁所内存中获取数据,设立了多级缓存(寄存器)。如果在缓存中找不到数据时,才去内存中寻找数据。 所以此时考虑`i++`的情况,当有线程A和线程B同时执行上面的代码时,它们首先将 i 的值读到寄存器中,然后在各自对寄存器中的值进行修改,最后刷新到主内存中,如此便造成刷新到主存的值相同,这便产生线程安全问题。
解决方案
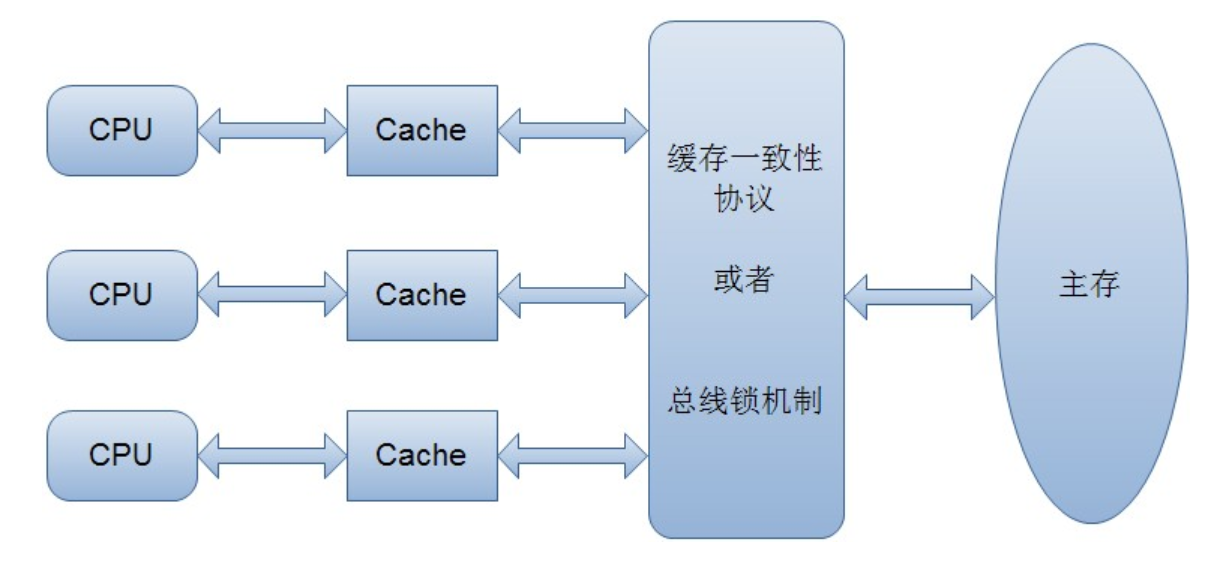
1)**通过在总线加LOCK\#锁的方式** 在计算机中,总线是传输数据的通道,倘若一个线程在传输数据时,其他线程看到有线程正在使用总线,那么其他线程等待这个线程执行完在使用总线。此时回到`i++`的场景,线程A读取 i 的值放到自己的寄存器后,线程B也要读取,发现线程A正在读取中,那么其阻塞。然后线程A修改 i 的值传入到主存中,线程B才能开始读取,此时便可以解决线程安全问题。 但是如果锁主主线的话,导致其他与此数据无关的线程也无法传输数据,那么效率很低下。 2)**通过缓存一致性协议** 缓存一致性协议指:当CPU写数据时,如果发现操作的变量是共享变量(即在其他CPU中也存在该变量的副本),其他CPU通过嗅探机制发现该变量被修改后,则将其的缓存行设置为无效状态,因此当其他CPU需要读取这个变量时,如果发现自己缓存中缓存该变量的缓存行是无效的,那么就会从内存重新读取。





























")




还没有评论,来说两句吧...