Java8 Stream流操作
java8中的流式操作是一个很重要的内容
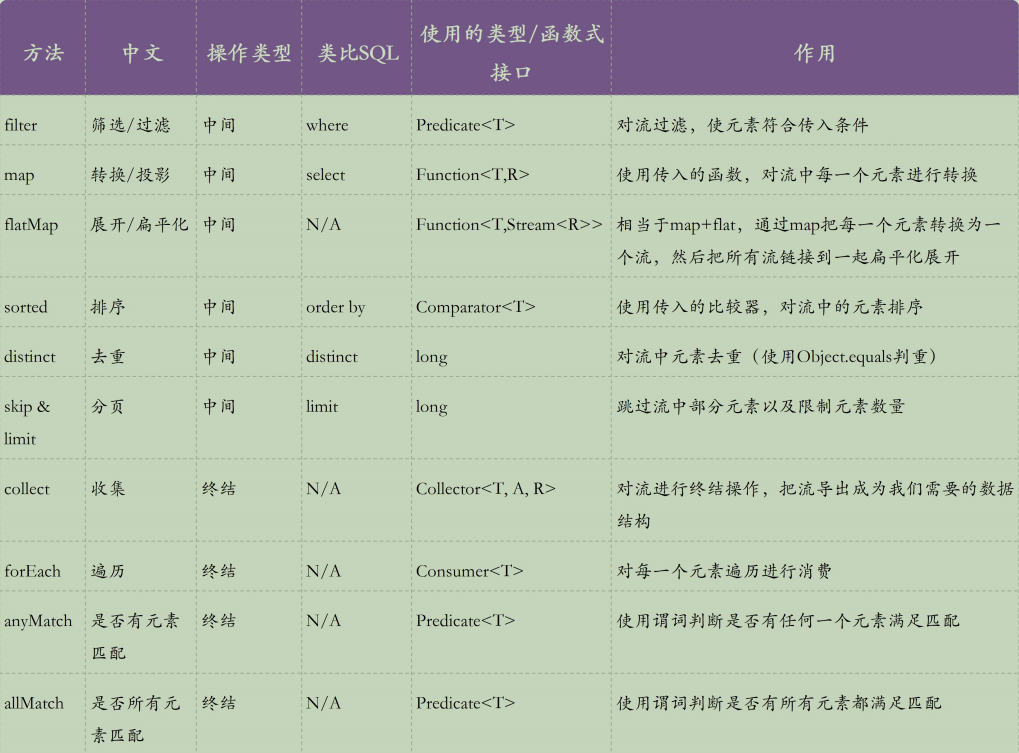
上图列出了stream主要流操作,我们可以看到,其实流操作可以类比我们的sql语句,如filter就类似于sql的where语句,我们就知道filter是对流进行过滤的,传入了一个Predicate断言接口,过滤掉断言为false的数据。相比一起的循环迭代,移除不符合的数据,是不是更加方便。下面我们来详细说说。
1、filter
过滤,传入一个Predicate
@Testpublic void testFilter() {Stream<Integer> stream = Stream.iterate(2, i -> i * 2).limit(10);// 过滤出小于10的数据stream.filter(i -> i < 10).forEach(System.out::println);}
执行结果: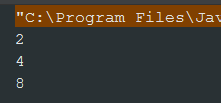
2、Map类似于sql的select,对数据进行转换
如下面的mapToObj
Stream mapToObj(IntFunction<? extends U> mapper);
传入的是IntFunction函数式接口,该接口你需要实现apply接口,根据一个int值转换成对象R
@FunctionalInterfacepublic interface IntFunction<R> {/** * Applies this function to the given argument. * * @param value the function argument * @return the function result */R apply(int value);}@Testpublic void testMap() {/** * 结果为: * java8.test.OrderItem@64cee07[priductId=1,price=1.0,quantity=1] * java8.test.OrderItem@1761e840[priductId=2,price=2.0,quantity=2] * java8.test.OrderItem@6c629d6e[priductId=3,price=3.0,quantity=3] * java8.test.OrderItem@5ecddf8f[priductId=4,price=4.0,quantity=4] * java8.test.OrderItem@3f102e87[priductId=5,price=5.0,quantity=5] * java8.test.OrderItem@27abe2cd[priductId=6,price=6.0,quantity=6] * java8.test.OrderItem@5f5a92bb[priductId=7,price=7.0,quantity=7] * java8.test.OrderItem@6fdb1f78[priductId=8,price=8.0,quantity=8] * java8.test.OrderItem@51016012[priductId=9,price=9.0,quantity=9] * java8.test.OrderItem@29444d75[priductId=10,price=10.0,quantity=10] */IntStream.rangeClosed(1, 10).mapToObj(i -> new OrderItem(Long.parseLong(Integer.toString(i)), i * 1.0, i)).forEach(System.out::println);/** * 结果为:55 * mapToInt需要实现根据对象转为int的接口方法 */Stream<OrderItem> stream = IntStream.rangeClosed(1, 10).mapToObj(i -> new OrderItem(Long.parseLong(Integer.toString(i)), i * 1.0, i));System.out.println(stream.mapToInt(OrderItem::getQuantity).sum());}
3、flatMap主要对嵌套对象的展开成stream然后统一处理
如下例中有一个订单列表,每个订单中有多个商品,先要对多笔订单中商品的总数量进行统计。
flatMapToInt、flatMapToDouble本质上与先flatMap,再mapToInt、mapToDouble是一样的,代码长度也基本一样。
@Testpublic void testFlatMap() {// 数据准备List<OrderItem> orderItemList =IntStream.rangeClosed(1, 10).mapToObj(i -> new OrderItem(Long.parseLong(Integer.toString(i)), i * 1.0, i)).collect(Collectors.toList());List<Order> orderList =IntStream.rangeClosed(1, 10).mapToObj(i -> new Order(orderItemList)).collect(Collectors.toList());// 所有明细的数量之和 flatMapSystem.out.println(orderList.stream().flatMap(order -> order.getOrderItemList().stream()).mapToInt(OrderItem::getQuantity).sum());// 所有明细的数量之和 flatMapToIntSystem.out.println(orderList.stream().flatMapToInt(order -> order.getOrderItemList().stream().mapToInt(OrderItem::getQuantity)).sum());}
4、Sorted对流中的数据进行排序 Stream sorted(Comparator<? super T> comparator);
@Testpublic void testSorted() {Stream<Integer> stream = Stream.iterate(2, i -> i * 2).limit(20);// 找出大于100,但较小的前3个数stream.filter(i -> i > 100).sorted(Integer::compareTo).limit(3).forEach(System.out::println);}
执行结果: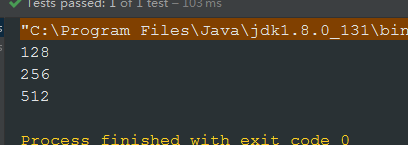
5、distinct对流中的数据进行去重,类似sql的distinct
@Testpublic void testDistinct() {Stream<Integer> stream = Stream.generate(() -> 2).limit(20);stream.distinct().forEach(System.out::println);}
执行结果: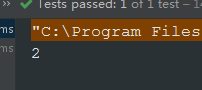
6、Skip和limit
/** * Skip和limit常用来分页,skip指跳过一定数据,limit为限制多少条数据 */@Testpublic void testSkipAndLimit() {Stream<Integer> stream = Stream.iterate(2, i -> i * 2).limit(20);// 查找前三个数据stream.limit(3).forEach(System.out::println);//查找第3到第5个数据stream.skip(2).limit(3).forEach(System.out::println);}
执行结果:
报错了,说stream已经打开或关闭了。说明我们创建的stream只能使用一次,每次要重新创建。这里可以采用Supplier接口实现重用,如下
/** * Skip和limit常用来分页,skip指跳过一定数据,limit为限制多少条数据 */@Testpublic void testSkipAndLimit1() {Supplier<Stream<Integer>> supplier = () -> Stream.iterate(2, i -> i * 2).limit(20);// 查找前三个数据supplier.get().limit(3).forEach(System.out::println);//查找第3到第5个数据supplier.get().skip(2).limit(3).forEach(System.out::println);}
执行结果: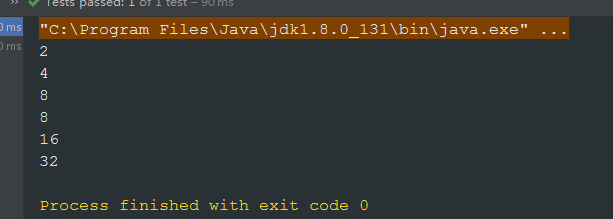
7、Collect操作
/** * 流的终结操作,可以将流转化为list,set,map等 */@Testpublic void testCollect() {List<OrderItem> orderItemsList =IntStream.rangeClosed(1, 10).mapToObj(i -> new OrderItem(Long.parseLong(Integer.toString(i)), i * 1.0, i)).collect(Collectors.toList());Set<OrderItem> orderItemsSet =IntStream.rangeClosed(1, 10).mapToObj(i -> new OrderItem(Long.parseLong(Integer.toString(i)), i * 1.0, i)).collect(Collectors.toSet());Map<Long, OrderItem> orderItemsMap =IntStream.rangeClosed(1, 10).mapToObj(i -> new OrderItem(Long.parseLong(Integer.toString(i)), i * 1.0, i)).collect(Collectors.toMap(OrderItem::getPriductId, item -> item));System.out.println(orderItemsMap.get(new Long(1)));}
有关collect的操作可以参看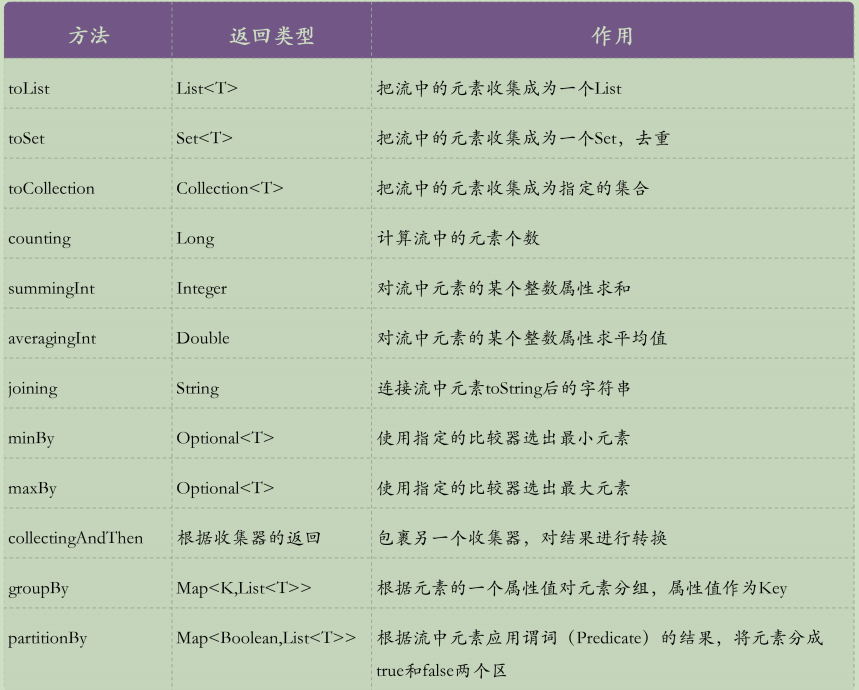
7.1、groupingBy分组,结果为map。 partitioningBy是分区,结果也是map,但只有两组
@Testpublic void testGroupBy() {Supplier<Stream<Integer>> supplier = () -> Stream.iterate(1, i -> i * 3).limit(20);// 对数字进行分组,对每个数字进行分组,所以会是20组Map map = supplier.get().collect(Collectors.groupingBy(i -> i));// 对奇数偶数进行分组 partitioningBy接受的是断言,返回的map只有两组,key分别为true和falseMap map1 = supplier.get().collect(Collectors.partitioningBy(i -> (i & 1) == 0));}
执行结果: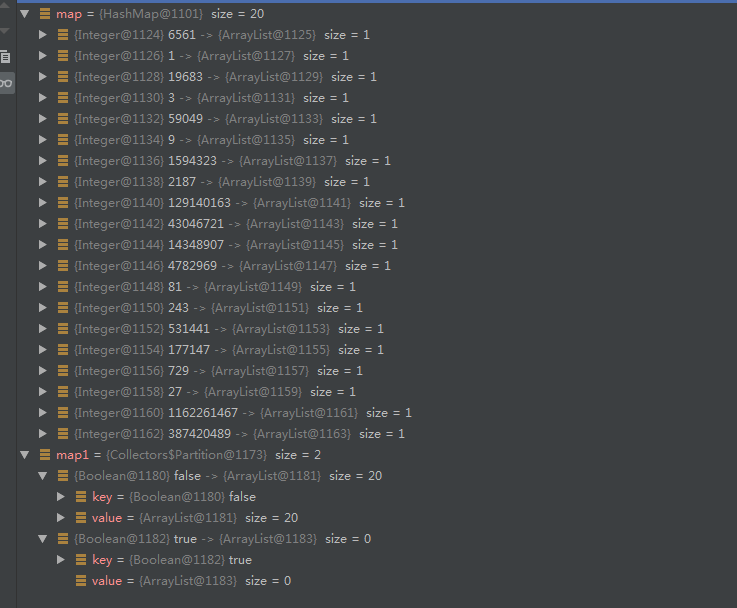


























及SPRO的使用技巧")







还没有评论,来说两句吧...